Otros enlaces:
|
- Teoría de la Información Algorítmica
- Máquinas de Turing y el Problema de la Parada
- Tesis de Church-Turing
- Máquinas de Turing Universales
- Complejidad de Kolmogorov
- Otros Conceptos
- Programas y Códigos Auto-Delimitantes
- Selección de UTM
- Probabilidad de Parada de Chaitin: Omega
- Referencias
- Enlaces
Teoría de la Información Algorítmica
Gregory Chaitin[1], Ray Solomonoff, y Andrei Kolmogorov desarrollaron una visión diferente de la información con respecto a la de Shannon. En lugar de considerar el conjunto estadístico de mensajes de una fuente de información, la teoría de la información algorítmica examina secuencias individuales de símbolos. Aquí, la información H(X) se define como el tamaño mínimo de un programa necesario para generar la secuencia X.
Este artículo destaca algunos de los conceptos principales de la Teoría de la Información Algorítmica. El conocimiento de este tema puede ser útil al debatir con creacionistas cuyo uso de conceptos de tanto la Teoría de la Información Clásica como la Teoría de la Información Algorítmica podría ser impreciso. Este artículo es solo una revisión de las ideas principales. Para las demostraciones matemáticas y un fondo más detallado, consulte el material citado y los enlaces.
Máquinas de Turing y el Problema de la Parada[Inicio]
Comprender la Teoría de la Información Algebraica requiere conocimientos de Máquinas de Turing. Alan Turing[2] demostró que es posible inventar una única máquina U capaz de calcular cualquier secuencia computable. Las notaciones de Turing son algo difíciles, pero la idea básica es la siguiente:
Los elementos de una Máquina de Turing son una cinta de programa con una cabeza de lectura, una cinta de trabajo con una cabeza de lectura/escritura, un estado (representado por un número), una tabla de estados y una tabla de acciones. La cinta de programa tiene longitud finita y contiene una secuencia de símbolos. La cinta de trabajo está inicialmente en blanco. Para cada ciclo de la máquina, el estado se reemplaza por el valor de búsqueda en la tabla de estados. El índice de búsqueda es una combinación del estado actual, y del símbolo leído de la cinta de programa, y del símbolo leído de la cinta de trabajo.
La tabla de acciones controla las cintas. Las siguientes acciones están permitidas:
- Detenerse
- Avanzar la cinta del programa un símbolo a la derecha
- Avanzar la cinta de trabajo un símbolo a la derecha
- Rebobinar la cinta de trabajo un símbolo a la izquierda
- Borrar el símbolo actual en la cinta de trabajo
- Escribir cualquiera de los símbolos R en la cinta de trabajo (hay R de estas acciones).
Podemos pensar en las cintas de la Máquina de Turing como cadenas; es decir, secuencias de símbolos. Llamaremos a la cadena del programa p, y a la cadena de salida resultante en la cinta de trabajo X. El programa p produce la cadena X en la Máquina de Turing T. Dado que tenemos la Máquina de Turing T, la cadena X puede representarse mediante p. También podemos pensar en p y X como números, ya que los números se representan como secuencias de símbolos.
A menudo, estamos hablando de Máquinas de Turing binarias, para las cuales el conjunto de símbolos en las dos cintas consiste en 0 y 1. Sin embargo, esto no tiene por qué ser así. Podemos tener cualquier número de símbolos. Ahora, obviamente, no podemos tener realmente una cinta de trabajo infinitamente larga, pero la Máquina de Turing se utiliza para problemas teóricos, por lo que podemos imaginar que lo hacemos.
A continuación se muestra un diagrama de una Máquina de Turing:
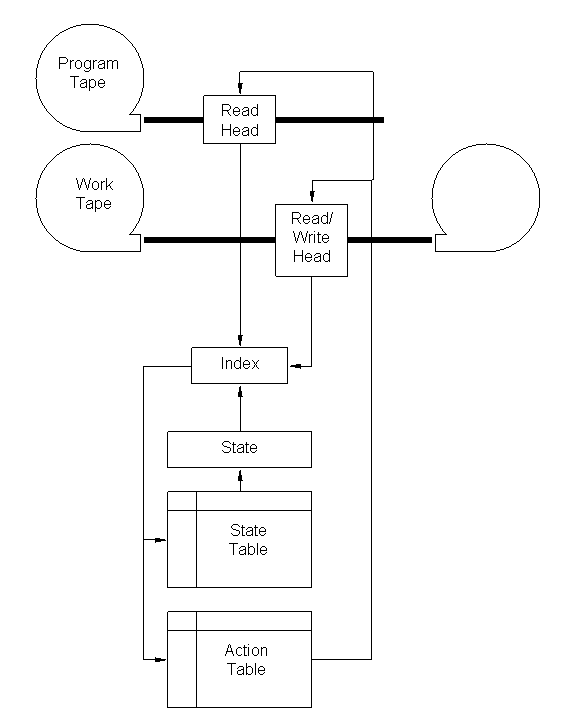 |
Para una buena descripción de las máquinas de Turing, véase la Enciclopedia de Filosofía de Stanford[3]. Tenga en cuenta que las máquinas teóricas de Turing tienen cintas de trabajo infinitas, lo cual, por supuesto, no puede construirse. Algunos problemas no son, por lo tanto, posibles de ejecutar en máquinas de Turing físicas reales.
Turing inventó su máquina teórica para abordar el Entscheidungsproblem o problema de decisión; es decir, si es posible en la lógica simbólica encontrar un algoritmo general que determine, para enunciados de primer orden dados, si son universalmente válidos o no.
Las raíces modernas del Entscheidungsproblem se remontan a un discurso de 1900 de David Hilbert. [4] Hilbert había esperado que fuera posible desarrollar un algoritmo general para decidir si un conjunto de axiomas era contradictorio. Kurt Gödel [5] demostró que, en cualquier sistema axiomático para la aritmética de los números naturales, existen algunas proposiciones que no pueden ser demostradas o refutadas dentro de los axiomas del sistema. Esto es conocido como el Teorema de la Incompletitud de Gödel, y demostró que el Segundo Problema de Hilbert no podía resolverse.
Turing, basándose en el trabajo de Gödel, demostró que el Entscheidungsproblem no era resoluble. Alonzo Church, de forma independiente a Turing, demostró lo mismo.
Turing utilizó el problema de la parada para su demostración. El problema de la parada es un problema de decisión. Plantea la pregunta: dada una descripción de un algoritmo y sus condiciones iniciales, ¿se puede demostrar que el algoritmo se detendrá? Un algoritmo que genere los dígitos de π es un ejemplo de un algoritmo no detenedor (π es un número irracional y transcendental; no puede expresarse como un polinomio con coeficientes racionales y, por lo tanto, tiene un número infinito de dígitos). Turing demostró que no existe ningún algoritmo general que pueda resolver el problema de la parada para todas las entradas posibles, y por consiguiente que el Entscheidungsproblem es irresoluble.
Tesis de Church-Turing [Inicio]
La Tesis de Church-Turing es una síntesis de la Tesis de Church y la Tesis de Turing. Esencialmente, establece que, siempre que exista un método efectivo para obtener los valores de una función matemática, la función puede ser computada por una máquina de Turing. La idea básica es que, si tienes un cálculo que puede ser computado por cualquier máquina (determinista) que pueda ser implementada efectivamente, una máquina de Turing puede realizar el cálculo.
Se han publicado dos visiones competidoras de la Tesis de Church-Turing por Copeland[6] y Hodges[7] (el argumento es, al menos en parte, sobre cuán fuertemente enunciada una tesis Church y Turing habrían acordado, y si aceptaron el concepto descrito por Gandy como Tesis M).
Máquina Universal de Turing [Inicio]
No sería práctico construir una nueva Máquina de Turing cada vez que se desea ejecutar un cálculo, dando lugar al concepto de Máquina de Turing Universal (MTU). Una Máquina de Turing Universal (MTU) se define como una Máquina de Turing que puede simular cualquier otra Máquina de Turing. Si tenemos una MTU, podemos programarla para que actúe como cualquier Máquina de Turing que deseemos.
Dado que una Máquina de Turing puede describirse mediante sus tablas de estado y acción, puede representarse como una cadena. Si p es un programa en una Máquina de Turing T que produce la cadena X en la cinta de trabajo, entonces en una Máquina de Turing Universal podemos cargar una representación en cadena de T, ejecutar el programa p y obtener X. Utilizaremos el símbolo u para la representación de T en U. Por lo tanto, si <u><p> es la entrada para U, esta produce X. Obsérvese que u depende tanto de T como de U, mientras que p depende de X y de T.
Existen un número infinito de Máquinas de Turing Universales. Algunas investigaciones se han dedicado a determinar cuán pequeñas pueden ser. Marvin Minsky descubrió una UTM de 7 estados y 4 símbolos en 1962[8]. Yurii Rogozhin ha descubierto un número de UTMs pequeñas[9]. Si las describimos como (m, n) donde m es el número de estados y n es el número de símbolos, Rogozhin ha añadido (24, 2), (10, 3), (5, 5), (4, 6), (3, 10) y (2, 18) a los de Minsky (7, 4). Stephen Wolfram reporta una UTM (2, 5) [10].
ComplejidadKolmogorov[ Inicio]
Kolmogorov, Chaitin y Solomonoff llegaron independientemente a la idea de representar la complejidad de una cadena basándose en su compresibilidad, representándola como un programa.
Dada una Máquina Universal de Turing U, el contenido de información algorítmica, también llamado complejidad algorítmica o Complejidad de Kolmogorov (KC) H(X) de la cadena X se define como la longitud del programa más corto p en U que produce la cadena X. El programa más corto capaz de producir una cadena se denomina programa elegante. El programa también puede denotarse X*, donde U(X*) = X, y puede considerarse a sí mismo una cadena. Dado un programa elegante X*,
H(X) = |X*|
donde |X*| es el tamaño de X*.
La terminología en la literatura es variable. Por ejemplo, algunos autores utilizan CM(X) o I(X) para H(X) en la máquina M, o I(X) para H(X), o min(p) para |X*|.
Una cadena X se dice que es aleatoriamente algorítmica si su programa elegante X* no puede expresarse de ninguna manera más corta que X; es decir, si su complejidad algorítmica es máxima. En otras palabras, no puede comprimirse en la UTM de referencia.
Una cadena aleatoria algorítmicamente infinita no contiene datos redundantes. Se puede demostrar que la proporción de cada símbolo en la cadena es aproximadamente igual, con una distribución aleatoria. Si tal cadena representa un número entre 0 y 1 (el intervalo unitario), entonces el número es un número normal o Borel normal después del trabajo de Emile Borel.
No todos los números normales son aleatorios algorítmicamente. Un número puede ser normal pero definido como un programa corto en alguna UTM. De manera similar, no todos los números aleatorios algorítmicamente son normales. Las cadenas de longitud finita se permiten ser aleatorias algorítmicamente por definición. Cualquier cadena de longitud finita puede tomarse como un número racional en alguna base, y los números racionales no pueden ser normales en ninguna base.
Deben hacerse varios puntos sobre la complejidad de Kolmogorov:
- El KC no puede
computarse. Cuando estamos probando si un programa p generará
la cadena X en U, nunca sabremos si
p se detendrá (como demostró Turing). Incluso si hemos
encontrado un programa p1 que genera X en
U, no podemos saber si existe un programa más corto
p0 que genera X en U. Se puede
estimar los límites para el KC, pero el cálculo absoluto del KC para una
cadena es teóricamente imposible.
- El KC depende de
la UTM de referencia seleccionada, no solo de la cadena. Si tienes
dos UTM U y V, la longitud del programa más corto
pU para producir X en U no tiene
que coincidir con la longitud del programa más corto
pV para producir X en V. En otras
palabras, HU(X) no es igual a
HV(X) en general. Normalmente, esto
no importa porque la UTM de referencia se da y toda la discusión es relativa a ella, o hay una suposición implícita de que cualquier UTM seleccionada tendrá un sobrecosto pequeño relativo a las cadenas aleatorias algorítmicamente muy grandes bajo discusión. Esto sí importa cuando no tienes una UTM de referencia y no estás hablando de cadenas aleatorias algorítmicamente muy grandes (ver abajo, bajo Selección de UTM).
- Deben existir
cadenas aleatorias algorítmicamente. Esto es una consecuencia del
Principio de las Casillas Chinas. Hay 2n
cadenas de longitud n, y
2n-1 programas de longitud menor que n.
Simplemente no hay suficientes programas más cortos para generar todas
las 2n cadenas de longitud n.
- La mayoría de las
cadenas están al menos cerca de ser aleatorias algorítmicamente. Esto es otra
consecuencia del Principio de las Casillas Chinas. Hay
2n-k-1 programas de longitud menor que
n-k, y 2n - (2n-k) =
2n(1-2-k) programas de longitud entre
n-k y n. Sea k = 10. Al menos el 99.9% de las cadenas de
longitud n tienen un KC de al menos n-10.
- El KC está acotado
por la longitud de la cadena más una constante. Un programa muy simple es
imprimir X. Su sobrecosto en una UTM dada es una constante
c. El KC para cualquier cadena en esa UTM no puede exceder la
longitud de la cadena + c. La constante depende de la
UTM.
- Teorema de
Invariancia. Si tenemos una UTM U y cualquier otra TM V,
HU(X) ≤HV(X) + c para
todas las X. La constante c depende de U y
V pero no de X.
- Aleatorio algorítmicamente no es lo mismo que
aleatorio estadísticamente. Pensamos en lanzar monedas, tirar dados y la desintegración atómica como procesos no determinísticos o estocásticos, y llamamos a esto aleatorio. Aleatorio algorítmicamente tiene una definición diferente y es un concepto diferente, aunque las cadenas aleatorias algorítmicamente muy largas tienen distribuciones de símbolos con propiedades estadísticas. Las cadenas aleatorias algorítmicamente son o bien computables y determinísticas, o no computables.
- El KC no es lo mismo que la complejidad computacional. Teoría de la complejidad computacional se ocupa de la cantidad de recursos de computación (tiempo y memoria) necesarios para resolver un problema. La complejidad computacional no está relacionada con si una cadena es comprimible en una UTM dada.
Algunos otros conceptos [Inicio]
Información Conjunta Contenido. Supongamos que tuviéramos una UTM con dos cintas de trabajo en lugar de una. Un programa podría producir dos cadenas, una en cada cinta de trabajo. Alternativamente, podría producir dos cadenas en una sola cinta de trabajo, una tras otra (posiblemente separadas por un espacio en blanco). O podríamos ejecutar el mismo programa en dos UTMs diferentes ejecutándose en paralelo. De cualquier manera, tenemos un programa que produce dos cadenas. El contenido de información conjunta H(X,Y) de las cadenas X y Y es el tamaño del programa más pequeño para producir simultáneamente tanto X como Y.
Contenido de información condicional. El condicional o relativo contenido de información H(X|Y) es el tamaño del programa más pequeño para producir X a partir de un programa mínimo para Y. Observe que H(X|Y) requiere Y* y no Y. Chaitin demostró que:
H(X,Y) ≤ H(X) + H(Y|X) + O(1)
donde O(1) es una constante que representa el sobrecarga computacional.
Contenido de Información Mutua. El contenido de información mutua H(X : Y) se calcula mediante cualquiera de los siguientes métodos:
H(X : Y) = H(X) + H(Y) - H(X,Y)
H(X : Y) = H(X) - H(X|Y) + O(1)
H(X : Y) = H(Y) - H(Y|X) + O(1)
Las cadenas X y Y son independientes algorítmicamente si
H(X,Y) ≈ H(X) + H(Y)
en cuyo caso el contenido de información mutua es pequeño.
Debe enfatizarse que, a pesar de la similitud en la notación y forma con la Teoría de la Información Clásica, la Teoría de la Información Algorítmica se ocupa de cadenas individuales, mientras que la Teoría de la Información Clásica se ocupa del comportamiento estadístico de las fuentes de información. Se puede establecer una relación entre la Complejidad de Kolmogorov promedio y la entropía de Shannon, pero no entre la KC y la entropía de Shannon.
Programas y Códigos Auto-Delimitantes [Inicio]
Un problema que debemos resolver para nuestra UTM U es cómo distinguir entre u, la representación de una Máquina de Turing, y p, el programa que genera la cadena X. Un método para hacer esto es representar u mediante un código auto-delimitante. Un ejemplo es el código unario, en el que el número N se representa mediante N-1 ceros seguidos de un único 1. En otras palabras, 1 = 1, 2 = 01, 3 = 001, 4 = 0001, y así sucesivamente. El código unario es ineficiente si se tienen muchos números grandes, pero en algunos casos puede ser una buena opción.
Otro ejemplo es añadir un símbolo al conjunto de símbolos, cuyo significado es fin. Si u se representa como un número binario, necesitamos un conjunto de tres símbolos para el u delimitado. Los códigos 0101101001e y 01011e pueden distinguirse, aunque 01011 parezca el inicio de 0101101001.
De manera similar, si representamos un conjunto de símbolos mediante un código binario (como ASCII), podemos reservar una representación binaria para el símbolo final (como el símbolo EOF de ASCII). El caso más simple consiste en utilizar una secuencia de 2 bits que represente los dos símbolos binarios 0 y 1 más el símbolo final (00 = 0, 11 = 1, 01 = final).
Los códigos auto-delimitantes a veces se llaman códigos prefijo, porque ningún código es un prefijo de otro código.
Selección de UTM [Inicio]
Recuerde que la Complejidad de Kolmogorov (la longitud del programa más corto en una UTM para calcular una cadena) depende de la selección de la UTM. En la Teoría de la Información Algorítmica, esto usualmente no importa. Recuerde que el límite superior de la CK para una cadena está acotado por una constante c, que es el sobrecosto para representar una MT que implementa "imprimir X" en la UTM de referencia. Mientras elijamos una UTM de referencia para la cual este sobrecosto sea muy pequeño en relación con la longitud de las cadenas con las que estamos trabajando, podemos ignorar la constante. Por ejemplo, si estamos trabajando con |X| > 1 millón y c < cien, podemos ignorar c.
Alternativamente, si toda la discusión se refiere a un sistema de coordenadas UTM dado, entonces c representa un desplazamiento fijo respecto a nuestro límite superior, y para muchos tipos de discusiones teóricas podemos omitirlo.
En general, si no hemos seleccionado una de las infinitas UTM como referencia, no podemos ignorar la constante. Nada nos obliga a utilizar una UTM para la cual c es pequeña. En otras palabras, existen UTM en las que "imprimir X" no puede codificarse eficientemente.
El siguiente diagrama ilustra el problema, que se remonta al Principio de las Casillas. Supongamos que tenemos tres diferentes UTMs, U, V y W, todos los cuales mapean el conjunto de programas posibles {up} al conjunto de cadenas finitas posibles {X}. Dado que solo nos preocupamos por la longitud de la cadena de entrada, no nos importa la diferencia en los descriptores de TM en U, V y W.
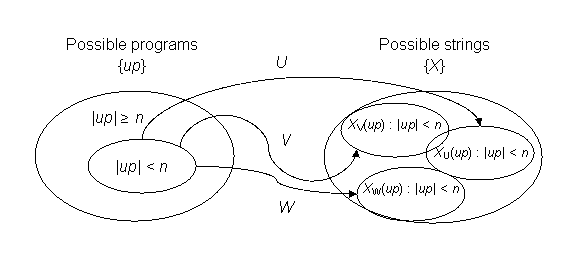 |
Para el conjunto de cadenas de entrada donde |up| < n, cada UTM debe mapear como máximo 2n cadenas en {X} gracias al Principio de las Palomas. Las regiones objetivo en {X} para U, V y W pueden o no superponerse. No tienen que hacerlo. Dado que tenemos un número infinito de UTMs de los cuales elegir, podemos imaginar que cualquier mapeo es posible, y esto de hecho puede demostrarse.
Primero, considera el siguiente tipo de Máquina de Turing: lee un programa de entrada p como un número, que su tabla de estados utiliza para iniciar una secuencia. Cada paso en la secuencia emite un símbolo sin referencia adicional a la cinta del programa o a la cinta de trabajo, y luego se detiene. Esto implementa una búsqueda en tabla. Si la MT lee N números diferentes, puede emitir N cadenas de longitud arbitraria. Podríamos construir una MT que emita cadenas después de leer programas de 2 bits de la siguiente manera:
|
Programa de entrada |
Cadena de salida |
|
00 |
1011100001001111001 |
|
01 |
1010 |
|
10 |
0000011110110 |
|
11 |
1 |
El tamaño mínimo de una tabla es, por supuesto, una tabla con una sola entrada, por lo que con este tipo de Máquina de Turing podemos generar cualquier cadena con un programa de 1 bit de longitud.
Realmente no hay límite para la longitud de la cadena de salida de una tabla de búsqueda TM. Simplemente necesitamos una tabla lo suficientemente grande, lo que nos lleva al siguiente problema: el tamaño de la tabla de búsqueda excede su cadena más larga. En otras palabras, generalmente esperaríamos que la cadena necesaria para describir la TM fuera mucho más larga que cualquier cadena que pueda producir. Ahí es donde la selección de UTM se vuelve crítica.
El problema es, ¿cómo codificamos la selección de la TM para ejecutarla en la UTM? Dado que la descripción de nuestra TM en la UTM es una cadena, también es un número. La UTM ejecutará la TM 1, la TM 2, la TM 3, … la TM N, etc., dependiendo de qué número se cargue en la UTM. Podemos diseñar una UTM que rebote casi en cualquier lugar de su tabla de estados cuando lee el descriptor de la TM u, por lo que cualquier mapeo desde u a la TM implementada es posible. De hecho, podríamos usar nuevamente la búsqueda en tabla.
Diseñaremos una UTM llamada MFTM, o Mi Máquina de Turing Favorita. MFTM tiene una tabla de estados y acciones dividida. La primera parte está dedicada a una única implementación integrada de una MT, cualquiera que decidamos que sea nuestra favorita. La otra parte implementa cualquier otra UTM Z elegida arbitrariamente. MFTM lee la cadena de entrada <a><q>. Si a es un 0, ejecuta q en la MT integrada. Si a es cualquier otro símbolo, ejecuta <q> = <z><p> en Z, donde z es un descriptor de una MT en Z y p es un programa.
Si incorporamos una tabla de búsqueda en MFTM, puede generar secuencias arbitrarias a partir de entradas muy cortas. El programa más corto en MFTM sería de 2 bits si incorporamos una tabla de 1 entrada. MFTM no viola el Principio de las Jaulas de Colombo, porque cualquier <u><p> en Z debe alargarse en 1 bit en MFTM. La KC de cada cadena no incorporada en la tabla aumenta en 1 bit.
Ahora, esto es admitidamente una manera astuta de obtener una baja Complejidad de Kolmogorov para cualquier cadena arbitraria, pero ilustra el problema. Dado que tenemos un número infinito de UTMs, y hay un número infinito de formas de codificar los descriptores de TM en UTMs, incluyendo códigos auto-delimitantes para los cuales algunos descriptores son inherentemente cortos, existen UTMs para los cuales conjuntos arbitrarios de cadenas finitas no son aleatorios algorítmicamente. Esto es importante, porque demuestra cuán fuertemente la KC puede depender de la selección del UTM. El descriptor del UTM no se incluye en el cálculo de la KC.
Es posible también diseñar una UTM en la que las cadenas tengan una KC arbitrariamente grande. Diseñaremos una UTM llamada RIM, o Máquina Realmente Ineficiente. Utilizará un código auto-delimitante para describir las TM, y este código tendrá la peor eficiencia que podamos inventar. En lugar de codificar 0 como 00, 1 como 11 y end como 01, codificaremos 0 como una cadena sucesiva de n 0's, 1 como una cadena sucesiva de n 1's, y end como cualquier otra subcadena de longitud n. Podemos hacer que n sea muy grande, como 1020. Aunque podríamos codificar T como u con q bits, RIM no puede cargar T con menos de nq bits. Eso significa que nq es una cota inferior para la KC en RIM.
Esta es una forma astuta de obtener una alta Complejidad de Kolmogorov para cualquier cadena arbitraria, pero nuevamente, ilustra el problema. RIM no viola el límite superior de la KC ni el Teorema de Invariancia, porque podemos permitir que la constante c sea muy grande. De hecho, lo hemos hecho artificialmente.
Probabilidad de parada de Chaitin: Ω(Omega)[Inicio]
Chaitin extendió el trabajo de Turing definiendo la probabilidad de parada. Considerando programas en una máquina de Turing universal U que no requieren entrada, definimos P como el conjunto de todos los programas en U que se detienen. Sea |p| la longitud de la cadena de bits que codifica el programa p, que es cualquier elemento de P. La probabilidad de parada o número Ω se define:
Ω= ∑2-|p| sobre todos los elementos p de P
Nuevamente, la notación de valor absoluto |p| denota el tamaño o longitud de la cadena de bits p.
Una forma de pensar sobre Ω es que, si alimentas una UTM con una cadena binaria aleatoria generada por un proceso Bernoulli 1/2 (como lanzar una moneda justa) como su programa, Ω es la probabilidad de que la UTM se detenga.
Como probabilidad, Ω tiene un valor entre 0 y 1. Chaitin demostró que Ω no solo es irracional y trascendental, sino que es un número real no computable. Es irreducible algorítmicamente o aleatorio algorítmicamente sin importar qué UTM elijas. No existe ningún algoritmo que pueda calcular sus dígitos.
Referencias[Inicio]
[1] Chaitin, G.J., Teoría de la Información Algorítmica. Tercera Impresión, Cambridge University Press, 1990. Disponible en línea.
[2] Turing, A.M., Sobre los Números Computables, con una Aplicación al Entscheidungsproblem. Proceedings of the LondonMathematical Society, ser. 2. vol. 42 (1936-7), pp.230-265; correcciones, Ibid, vol 43 (1937) pp. 544-546. Disponible en línea.
[3] en el SEP, Editores, "Máquina de Turing", The Stanford Encyclopedia of Philosophy (Spring 2002 Edition), Edward N. Zalta(ed.), URL =<http://plato.stanford.edu/archives/spr2002/entries/turing-machine/>
[4] Hilbert, D., Problemas Matemáticos: Conferencia Presentada ante el Congreso Internacional de Matemáticos en París en 1900, traducido por Maby Newson, Bulletin of the American Mathematical Society 8 (1902), pp. 437-479. , Versión HTML por D. Joyce disponible en línea.
[5] Gödel, K., Sobre Proposiciones Formalmente Indecidibles de Principia Mathematica y Sistemas Relacionados. Monatshefte für Mathematik und Physik, 38 (1931), pp. 173-198. Traducido en van Heijenoort: From Frege to Gödel. Harvard University Press, 1971.
[6] Copeland, B. Jack, "La Tesis de Church-Turing", The Stanford Encyclopedia of Philosophy (Fall 2002 Edition), Edward N. Zalta(ed.), URL = <http://plato.stanford.edu/archives/fall2002/entries/church-turing/>.
[7] Hodges, Andrew, "Alan Turing", The Stanford Encyclopedia of Philosophy (Summer 2002 Edition), Edward N. Zalta(ed.), URL = <http://plato.stanford.edu/archives/sum2002/entries/turing/>.
[8] Minsky, M., "Tamaño y Estructura de Máquinas de Turing Universales," Teoría de Funciones Recursivas, Proc. Symposium. en Matemáticas Puras, 5, American Mathematical Society, 1962, pp. 229-238.
[9] Rogozhin, Y. "Máquinas de Turing Universales Pequeñas." Theoretical Computer Science 168 iss. 2, 215-240, 1996.
[10] Wolfram, S. Una Nueva Ciencia. Champaign, IL: Wolfram Media, pp.706-711, 2002.
[Inicio]