Outros Links:
|
- Teoria da Informação Algorítmica
- Máquinas de Turing e o Problema da Parada
- Tese de Church-Turing
- Máquinas de Turing Universais
- Complexidade de Kolmogorov
- Outros Conceitos
- Programas e Códigos Auto-Delimitantes
- Seleção de UTM
- Probabilidade de Parada de Chaitin: Omega
- Referências
- Links
Teoria da Informação Algorítmica
Gregory Chaitin[1], Ray Solomonoff, e Andrei Kolmogorov desenvolveram uma visão diferente de informação em relação à de Shannon. Em vez de considerar o conjunto estatístico de mensagens de uma fonte de informação, a teoria da informação algorítmica examina sequências individuais de símbolos. Aqui, a informação H(X) é definida como o tamanho mínimo de um programa necessário para gerar a sequência X.
Este artigo destaca alguns dos principais conceitos da Teoria da Informação Algorítmica. O conhecimento deste assunto pode ser útil ao debater com criacionistas cujos usos de conceitos tanto da Teoria da Informação Clássica quanto da Teoria da Informação Algorítmica podem ser imprecisos. Este artigo é apenas uma revisão das ideias principais. Para as demonstrações matemáticas e um background mais detalhado, consulte o material citado e os links.
Máquinas de Turing e o Problema da Parada[Topo]
Entender a Teoria da Informação Algébrica requer conhecimento de Máquinas de Turing. Alan Turing[2] demonstrou que é possível inventar uma única máquina U capaz de calcular qualquer sequência computável. As notações de Turing são um pouco difíceis, mas a ideia básica é a seguinte:
Os elementos de uma Máquina de Turing são uma fita de programa com uma cabeça de leitura, uma fita de trabalho com uma cabeça de leitura/escrita, um estado (representado por um número), uma tabela de estados e uma tabela de ações. A fita de programa tem comprimento finito e contém uma sequência de símbolos. A fita de trabalho está inicialmente em branco. Para cada ciclo da máquina, o estado é substituído pelo valor de consulta na tabela de estados. O índice de consulta é uma combinação do estado atual, do símbolo lido da fita de programa e do símbolo lido da fita de trabalho.
A tabela de ações controla as fitas. As seguintes ações são permitidas:
- Parar
- Avançar a fita do programa um símbolo para a direita
- Avançar a fita de trabalho um símbolo para a direita
- Recuar a fita de trabalho um símbolo para a esquerda
- Apagar o símbolo atual na fita de trabalho
- Escrever qualquer um dos símbolos R na fita de trabalho (há R dessas ações).
Podemos pensar nas fitas da Máquina de Turing como strings; ou seja, sequências de símbolos. Chamaremos a string do programa p, e a string de saída resultante na fita de trabalho X. O programa p produz a string X na Máquina de Turing T. Dado que temos a Máquina de Turing T, a string X pode ser representada por p. Também podemos pensar em p e X como números, já que os números são representados como sequências de símbolos.
Muitas vezes, estamos falando de Máquinas de Turing binárias, para as quais o conjunto de símbolos nas duas fitas consiste em 0 e 1. No entanto, isso não precisa ser o caso. Podemos ter qualquer número de símbolos. Agora, obviamente, não podemos realmente ter uma fita de trabalho infinitamente longa, mas a Máquina de Turing é usada para problemas teóricos, então podemos imaginar que podemos.
Abaixo é mostrado um diagrama de uma Máquina de Turing:
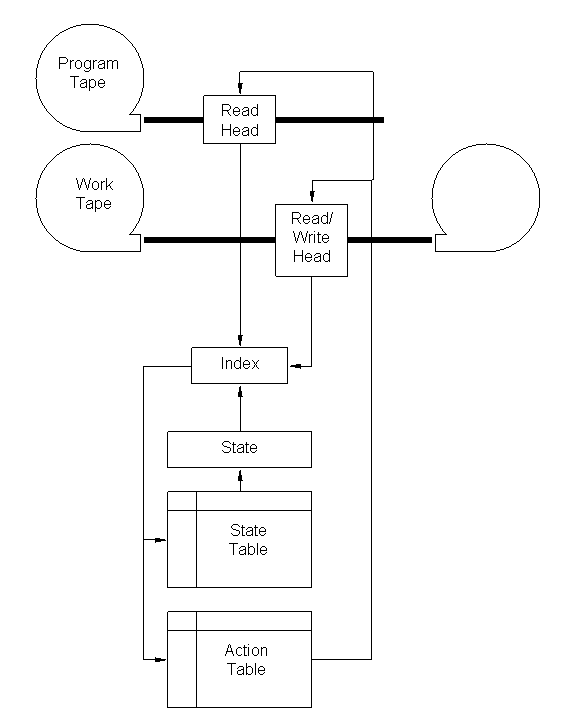 |
Para uma boa descrição de Máquinas de Turing, consulte a Stanford Encyclopedia of Philosophy[3]. Observe que as Máquinas de Turing teóricas possuem fitas de trabalho infinitas, o que, é claro, não pode ser construído. Alguns problemas não são, portanto, possíveis de serem executados em Máquinas de Turing físicas reais.
Turing inventou sua máquina teórica para abordar o Entscheidungsproblem ou problema da decisão; isto é, se é possível na lógica simbólica encontrar um algoritmo geral que decida, para enunciados de primeira ordem dados, se estes são universalmente válidos ou não.
As raízes modernas do Entscheidungsproblem remontam a um discurso de 1900 de David Hilbert. [4] Hilbert havia esperado que fosse possível desenvolver um algoritmo geral para decidir se um conjunto de axiomas era auto-contraditório. Kurt Gödel [5] mostrou que, em qualquer sistema axiomático para aritmética sobre números naturais, existem algumas proposições que não podem ser provadas ou refutadas dentro dos axiomas do sistema. Isso é conhecido como o Teorema da Incompletude de Gödel, e demonstrou que o Segundo Problema de Hilbert não poderia ser resolvido.
Turing, baseando-se no trabalho de Gödel, provou que o Entscheidungsproblem não era solucionável. Alonzo Church, independentemente de Turing, mostrou a mesma coisa.
Turing usou o problema da parada para sua prova. O problema da parada é um problema de decisão. Ele formula a seguinte questão: dada uma descrição de um algoritmo e suas condições iniciais, é possível demonstrar que o algoritmo irá parar? Um algoritmo que produz os dígitos de π é um exemplo de um algoritmo não parável (π é um número irracional e transcendental; não pode ser expresso como um polinômio com coeficientes racionais e, portanto, possui um número infinito de dígitos). Turing provou que não existe um algoritmo geral que possa resolver o problema da parada para todas as entradas possíveis, e, portanto, que o Entscheidungsproblem é insolúvel.
Tese de Church-Turing [Topo]
A Tese de Church-Turing é uma síntese da Tese de Church e da Tese de Turing. Ela essencialmente afirma que, sempre que existe um método eficaz para obter os valores de uma função matemática, a função pode ser calculada por uma máquina de Turing. A ideia básica é que, se você tem um cálculo que pode ser computado por qualquer máquina (determinística) que possa ser efetivamente implementada, uma máquina de Turing pode fazer o cálculo.
Dois pontos de vista concorrentes sobre a Tese de Church-Turing foram publicados por Copeland[6] e Hodges[7] (o argumento é, pelo menos em parte, sobre o quão fortemente enunciada uma tese Church e Turing concordariam em aceitar, e se eles aderiram ao conceito descrito por Gandy como Tese M).
Máquina Universal de Turing [Topo]
Não seria prático construir uma nova Máquina de Turing a cada vez que se deseja executar um cálculo, dando origem ao conceito de Máquina de Turing Universal (MTU). Uma Máquina de Turing Universal (MTU) é definida como uma Máquina de Turing que pode simular qualquer outra Máquina de Turing. Se tivermos uma MTU, podemos programá-la para agir como qualquer Máquina de Turing que desejarmos.
Como uma Máquina de Turing pode ser descrita por suas tabelas de estado e ação, ela pode ser representada como uma string. Se p for um programa em uma Máquina de Turing T que produz a string X na fita de trabalho, então em uma Máquina de Turing Universal podemos carregar uma representação em string de T, executar o programa p e obter X. Usaremos o símbolo u para a representação de T em U. Portanto, se <u><p> for a entrada para U, ele produzirá X. Observe que u depende tanto de T quanto de U, enquanto p depende de X e de T.
Existem um número infinito de Máquinas de Turing Universais. Algumas pesquisas foram realizadas para descobrir o quão pequenas elas podem ser. Marvin Minsky descobriu uma UTM de 7 estados e 4 símbolos em 1962[8]. Yurii Rogozhin descobriu um número de UTMs pequenas[9]. Se as descrevermos como (m, n) onde m é o número de estados e n é o número de símbolos, Rogozhin adicionou (24, 2), (10, 3), (5, 5), (4, 6), (3, 10) e (2, 18) aos de Minsky (7, 4). Stephen Wolfram relata uma UTM (2, 5) [10].
Complexidade de Kolmogorov[ Top]
Kolmogorov, Chaitin e Solomonoff chegaram independentemente à ideia de representar a complexidade de uma string com base em sua compressibilidade, representando-a como um programa.
Dada uma Máquina Universal de Turing U, o conteúdo informacional algorítmico, também chamado de complexidade algorítmica ou Complexidade de Kolmogorov (KC) H(X) da string X é definido como o comprimento do programa mais curto p em U que produz a string X. O programa mais curto capaz de produzir uma string é chamado de elegante. O programa também pode ser denotado X*, onde U(X*) = X, e pode ser considerado em si mesmo uma string. Dado um programa elegante X*,
H(X) = |X*|
onde |X*| é o tamanho de X*.
A terminologia na literatura é variável. Por exemplo, alguns autores usam CM(X) ou I(X) para H(X) na máquina M, ou I(X) para H(X), ou min(p) para |X*|.
Uma string X é dita ser aleatoriamente algorítmica se seu programa elegante X* não pode ser expresso de forma mais curta que X; isto é, se sua complexidade algorítmica é máxima. Em outras palavras, ela não pode ser comprimida na UTM de referência.
Uma string aleatória algorítmica infinitamente longa não contém dados redundantes. Pode-se demonstrar que a proporção de cada símbolo na string é aproximadamente igual, com uma distribuição aleatória. Se tal string representar um número entre 0 e 1 (o intervalo unitário), então o número é um número normal ou Borel normal, após o trabalho de Emile Borel.
Não todos os números normais são aleatórios algorítmicos. Um número pode ser normal, mas definido como um programa curto em alguma UTM. Da mesma forma, nem todos os números aleatórios algorítmicos são normais. Strings de comprimento finito são consideradas aleatórias algorítmicamente por definição. Qualquer string de comprimento finito pode ser tomada como um número racional em alguma base, e números racionais não podem ser normais em nenhuma base.
Devem ser feitas algumas observações sobre a Complexidade de Kolmogorov:
- O KC não pode ser
calculado. Quando estamos testando se um programa p irá
gerar a string X em U, nunca poderemos saber se
p irá parar (como Turing demonstrou). Mesmo que tenhamos
encontrado um programa p1 que gera X em
U, não poderemos saber se existe um programa mais curto
p0 que gera X em U. Pode-se
estimar limites para o KC, mas o cálculo absoluto do KC para uma
string é teoricamente impossível.
- O KC depende do
UTM de referência selecionado, não apenas da string. Se você tem
dois UTMs U e V, o comprimento do programa mais curto
pU para produzir X em U não precisa
corresponder ao comprimento do programa mais curto
pV para produzir X em V. Em outras
palavras, HU(X) não é igual a
HV(X) em geral. Normalmente, isso
não importa porque o UTM de referência é dado e toda discussão é
relativa a ele, ou há uma suposição implícita de que qualquer UTM
selecionado terá um overhead pequeno em relação às strings
algoritmicamente aleatórias muito grandes em discussão. Isso importa
quando você não tem um UTM de referência e não está falando sobre
strings algoritmicamente aleatórias muito grandes (veja abaixo, sob
Seleção de UTM).
- Devem existir
strings algoritmicamente aleatórias. Isso é uma consequência do
Princípio da Casa dos Pombos. Existem 2n
strings de comprimento n, e
2n-1 programas de comprimento menor que n.
Simplesmente não há programas mais curtos suficientes para gerar todas
as 2n strings de comprimento n.
- A maioria das
strings é pelo menos próxima de ser algoritmicamente aleatória.
Isso é outra consequência do Princípio da Casa dos Pombos.
Existem 2n-k-1 programas de comprimento menor que
n-k, e 2n - (2n-k) =
2n(1-2-k) programas de comprimento entre
n-k e n. Vamos dizer k = 10. Pelo menos 99,9% das strings de
comprimento n têm um KC de pelo menos n-10.
- O KC é limitado
pelo comprimento de uma string mais uma constante. Um programa
muito simples é imprimir X. Seu overhead em um UTM dado é uma
constante c. O KC para qualquer string naquele UTM não pode
exceder o comprimento da string + c. A constante depende do
UTM.
- Teorema da
Invariância. Se temos um UTM U e qualquer outra TM V,
HU(X) ≤HV(X) + c para
todas as X. A constante c depende de U e
V, mas não de X.
- Algoritmicamente
aleatório não é o mesmo que estatisticamente aleatório. Pensamos
em virar moedas, rolar dados e decaimento atômico como processos
não-determinísticos ou estocásticos, e chamamos isso de aleatório.
Aleatório algoritmicamente tem uma definição diferente e é um conceito
diferente, embora strings algoritmicamente aleatórias muito longas
tenham distribuições de símbolos com propriedades estatísticas. Strings
aleatórias algoritmicamente são ou computáveis e determinísticas, ou
incomputáveis.
- O KC não é o mesmo que complexidade computacional. Teoria da complexidade computacional lida com a quantidade de recursos de computação (tempo e memória) necessários para resolver um problema. A complexidade computacional não está relacionada ao fato de uma string ser compressível em um UTM dado.
Outros Conceitos [Topo]
Informação Conjunta Conteúdo. Suponha que tivéssemos uma UTM com duas fitas de trabalho em vez de uma. Um programa poderia produzir duas strings, uma em cada fita de trabalho. Alternativamente, poderia produzir duas strings em uma única fita de trabalho, uma após a outra (possivelmente separadas por um espaço em branco). Ou poderíamos executar o mesmo programa em duas UTMs diferentes rodando em paralelo. De qualquer forma, temos um programa produzindo duas strings. O conteúdo de informação conjunta H(X,Y) das strings X e Y é o tamanho do menor programa para produzir simultaneamente tanto X quanto Y.
Conteúdo Condicional de Informação. O condicional ou relativo conteúdo de informação H(X|Y) é o tamanho do menor programa para produzir X a partir de um programa mínimo para Y. Observe que H(X|Y) requer Y* e não Y. Chaitin mostrou que:
H(X,Y) ≤ H(X) + H(Y|X) + O(1)
onde O(1) é uma constante que representa o sobrecarga computacional.
Conteúdo de Informação Mútua. O conteúdo de informação mútua H(X : Y) é calculado por qualquer um dos seguintes:
H(X : Y) = H(X) + H(Y) - H(X,Y)
H(X : Y) = H(X) - H(X|Y) + O(1)
H(X : Y) = H(Y) - H(Y|X) + O(1)
As strings X e Y são independentes algorítmicamente se
H(X,Y) ≈ H(X) + H(Y)
neste caso, o conteúdo de informação mútua é pequeno.
Deve-se enfatizar que, apesar da semelhança na notação e forma com a Teoria da Informação Clássica, a Teoria da Informação Algorítmica lida com strings individuais, enquanto a Teoria da Informação Clássica lida com o comportamento estatístico de fontes de informação. Pode-se estabelecer uma relação entre a média da Complexidade de Kolmogorov e a entropia de Shannon, mas não entre a KC e a entropia de Shannon.
Programas e Códigos Auto-Delimitantes [Topo]
Um problema que devemos resolver para nossa UTM U é como distinguir entre u, a representação de uma Máquina de Turing, e p, o programa que gera a string X. Um método para fazer isso é representar u por um código auto-delimitante. Um exemplo é o código unário, no qual o número N é representado por N-1 zeros seguidos por um único 1. Em outras palavras, 1 = 1, 2 = 01, 3 = 001, 4 = 0001, e assim por diante. O código unário é ineficiente se você tiver muitos números grandes, mas em alguns casos pode ser uma boa escolha.
Outro exemplo é adicionar um símbolo ao conjunto de símbolos, cujo significado é fim. Se u for representado como um número binário, precisamos de um conjunto de três símbolos para o u delimitado. Os códigos 0101101001e e 01011e podem ser distinguidos, mesmo que 01011 pareça o início de 0101101001.
Da mesma forma, se representarmos um conjunto de símbolos por um código binário (como o ASCII), podemos reservar uma representação binária para o símbolo final (como o símbolo EOF do ASCII). O caso mais simples é usar uma sequência de 2 bits que representa os dois símbolos binários 0 e 1, mais o símbolo final (00 = 0, 11 = 1, 01 = final).
Códigos auto-delimitantes são às vezes chamados de códigos prefixo, porque nenhum código é um prefixo de qualquer outro código.
Seleção de UTM [Topo]
Lembre-se de que a Complexidade de Kolmogorov (o comprimento do programa mais curto em uma UTM para calcular uma string) depende da seleção da UTM. Na Teoria da Informação Algorítmica, isso geralmente não importa. Lembre-se de que o limite superior da CK para uma string é limitado por uma constante c, que é o overhead para representar uma TM que implementa "imprimir X" na UTM de referência. Desde que escolhamos uma UTM de referência para a qual este overhead seja muito pequeno em relação ao comprimento das strings com as quais estamos trabalhando, podemos ignorar a constante. Por exemplo, se estamos trabalhando com |X| > 1 milhão e c < cem, podemos ignorar c.
Alternativamente, se toda a discussão se refere a um determinado UTM de referência, então c representa um deslocamento fixo para nosso limite superior e, para muitos tipos de discussões teóricas, podemos omiti-lo.
Em geral, se não selecionamos uma das infinitas UTM como nossa referência, não podemos ignorar a constante. Nada nos obriga a usar uma UTM para a qual c é pequeno. Em outras palavras, existem UTM nas quais "imprimir X" não pode ser codificado eficientemente.
O diagrama a seguir ilustra o problema, que remonta ao Princípio da Gaveta. Suponha que tenhamos três UTM diferentes, U, V e W, todas as quais mapeiam o conjunto de programas possíveis {up} para o conjunto de strings finitas possíveis {X}. Como estamos preocupados apenas com o comprimento da string de entrada, não nos importa a diferença nos descritores de TM em U, V e W.
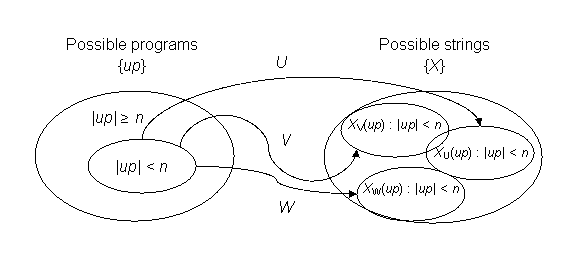 |
Para o conjunto de cadeias de entrada onde |up| < n, cada UTM deve mapear no máximo 2n cadeias em {X} graças ao Princípio das Casacas de Pombos. As regiões alvo em {X} para U, V e W podem ou não se sobrepor. Não precisam. Como temos um número infinito de UTMs para escolher, podemos imaginar que qualquer mapeamento é possível, e isso pode, de fato, ser demonstrado.
Primeiro, considere o seguinte tipo de Máquina de Turing: ela lê um programa de entrada p como um número, que sua tabela de estados usa para iniciar uma sequência. Cada passo na sequência produz um símbolo sem referência adicional à fita do programa ou à fita de trabalho, e então para. Isso implementa uma consulta de tabela. Se a MT lê N números diferentes, ela pode produzir N cadeias de caracteres de comprimento arbitrário. Poderíamos construir uma MT que produza cadeias de caracteres após ler programas de 2 bits da seguinte forma:
|
Programa de Entrada |
Cadeia de Saída |
|
00 |
1011100001001111001 |
|
01 |
1010 |
|
10 |
0000011110110 |
|
11 |
1 |
O menor tamanho de tabela é, naturalmente, uma tabela com uma entrada, então com este tipo de Máquina de Turing podemos gerar qualquer string com um programa de 1 bit.
Na verdade, não há limite para o comprimento da string de saída para uma tabela de consulta TM. Basta ter uma tabela grande o suficiente, o que nos leva ao seguinte problema: o tamanho da tabela de consulta excede sua string mais longa. Em outras palavras, geralmente esperaríamos que a string necessária para descrever a TM fosse muito mais longa do que qualquer string que ela possa produzir. É aí que a seleção de UTM se torna crítica.
O problema é, como codificamos a seleção da TM para executar na UTM? Como a descrição da nossa TM na UTM é uma string, ela também é um número. A UTM executará a TM 1, TM 2, TM 3, … TM N etc., dependendo de qual número é carregado na UTM. Podemos projetar uma UTM para pular praticamente para qualquer lugar em sua tabela de estados quando lê o descritor da TM u, de modo que qualquer mapeamento de u para a TM implementada seja possível. De fato, poderíamos novamente usar busca em tabela.
Vamos projetar uma UTM chamada MFTM, ou Minha Máquina de Turing Favorita. O MFTM possui uma tabela de estados e ações dividida. A primeira parte é dedicada a uma única implementação embutida de uma MT, seja qual for a que decidirmos ser a nossa favorita. A outra parte implementa qualquer outra UTM escolhida arbitrariamente Z. O MFTM lê a string de entrada <a><q>. Se a for um 0, executa q na MT embutida. Se a for qualquer outro símbolo, executa <q> = <z><p> em Z, onde z é um descritor de uma MT em Z e p é um programa.
Se incorporarmos uma tabela de consulta TM no MFTM, ele pode produzir sequências arbitrárias a partir de entradas muito curtas. O programa mais curto no MFTM seria de 2 bits se incorporarmos uma tabela com uma entrada. O MFTM não viola o Princípio das Casas de Pombos, porque qualquer <u><p> em Z deve ser alongado em 1 bit no MFTM. A KC de cada string não incorporada na tabela aumenta em 1 bit.
Agora, admito que esta é uma maneira astuta de obter baixa Complexidade de Kolmogorov para qualquer string arbitrária, mas ilustra o problema. Como temos um número infinito de UTMs, e há um número infinito de maneiras de codificar descritores de TM em UTMs, incluindo códigos auto-delimitantes para os quais alguns descritores são inerentemente curtos, existem UTMs para os quais conjuntos arbitrários de strings finitas não são aleatórios algorítmicos. Isso é importante, porque demonstra como fortemente a KC pode depender da seleção do UTM. O descritor do UTM não é incluído no cálculo da KC.
Também é possível projetar uma UTM na qual as strings têm KC arbitrariamente grande. Vamos projetar uma UTM chamada RIM, ou Máquina Realmente Ineficiente. Ela usará um código auto-delimitante para descrever as MMs, e este código terá a pior eficiência que possamos inventar. Em vez de codificar 0 como 00, 1 como 11 e end como 01, vamos codificar 0 como uma string sucessiva de n 0's, 1 como uma string sucessiva de n 1's, e end como qualquer outra substring de comprimento n. Podemos tornar n muito grande, como 1020. Mesmo que possamos codificar T como u com q bits, o RIM não pode carregar T em menos de nq bits. Isso significa que nq é um limite inferior para o KC no RIM.
Esta é uma maneira astuta de obter alta Complexidade de Kolmogorov para qualquer string arbitrária, mas, novamente, ilustra o problema. O RIM não viola o limite superior da KC ou o Teorema da Invariância, porque podemos deixar a constante c ficar muito grande. Na verdade, fizemos isso artificialmente.
Probabilidade de Parada de Chaitin: Ω(Omega)[Top]
Chaitin estendeu o trabalho de Turing ao definir a probabilidade de parada. Considerando programas em uma máquina de Turing universal U que não requerem entrada, definimos P como o conjunto de todos os programas em U que param. Seja |p| o comprimento da string de bits que codifica o programa p, que é qualquer elemento de P. A probabilidade de parada ou número Ω é definida:
Ω= ∑2-|p| para todos os elementos p de P
Novamente, a notação de valor absoluto |p| denota o tamanho ou comprimento da string de bits p.
Uma maneira de pensar sobre Ω é que, se você alimentar uma UTM com uma string binária aleatória gerada por um processo Bernoulli 1/2 (como lançar uma moeda justa) como seu programa, Ω é a probabilidade de que a UTM pare.
Como uma probabilidade, Ω tem um valor entre 0 e 1. Chaitin mostrou que Ω não é apenas irracional e transcendental, mas também um número real não computável. É irredutível algorítmica ou aleatória algorítmica, não importa qual UTM você escolha. Não existe nenhum algoritmo que possa calcular seus dígitos.
Referências[Topo]
[1] Chaitin, G.J., Teoria da Informação Algorítmica. Terceira Impressão, Cambridge University Press, 1990. Disponível on-line.
[2] Turing, A.M., Sobre Números Computáveis, com uma Aplicação ao Entscheidungsproblem. Proceedings of the LondonMathematical Society, ser. 2. vol. 42 (1936-7), pp.230-265; correções, Ibid, vol 43 (1937) pp. 544-546. Disponível on-line.
[3] na SEP, Editores, "Máquina de Turing", The Stanford Encyclopedia of Philosophy (Spring 2002 Edition), Edward N. Zalta(ed.), URL =<http://plato.stanford.edu/archives/spr2002/entries/turing-machine/>
[4] Hilbert, D., Problemas Matemáticos: Palestra Proferida perante o Congresso Internacional de Matemáticos em Paris em 1900, traduzido por Maby Newson, Bulletin of the American Mathematical Society 8 (1902), pp. 437-479. , versão HTML por D. Joyce disponível on-line.
[5] Gödel, K., Sobre Proposições Formalmente Indecidíveis de Principia Mathematica e Sistemas Relacionados. Monatshefte für Mathematik und Physik, 38 (1931), pp. 173-198. Traduzido em van Heijenoort: From Frege to Gödel. Harvard University Press, 1971.
[6] Copeland, B. Jack, "A Tese de Church-Turing", The Stanford Encyclopedia of Philosophy (Fall 2002 Edition), Edward N. Zalta(ed.), URL = <http://plato.stanford.edu/archives/fall2002/entries/church-turing/>.
[7] Hodges, Andrew, "Alan Turing", The Stanford Encyclopedia of Philosophy (Summer 2002 Edition), Edward N. Zalta(ed.), URL = <http://plato.stanford.edu/archives/sum2002/entries/turing/>.
[8] Minsky, M., "Size and Structure of Universal Turing Machines," Recursive Function Theory, Proc. Symposium. in Pure Mathematics, 5, American Mathematical Society, 1962, pp. 229-238.
[9] Rogozhin, Y. "Small Universal Turing Machines." Theoretical Computer Science 168 iss. 2, 215-240, 1996.
[10] Wolfram, S. Uma Nova Ciência. Champaign, IL: Wolfram Media, pp.706-711, 2002.
[Topo]