Erros Plagiados e Genética Molecular
Outro argumento no debate evolução-criacionismo
por Edward E. Max, M.D., Ph.D.O ensaio a seguir é uma atualização de um artigo que publiquei em Creation/Evolution em 1986 (XIX, p.34). Estou publicando-o com permissão de Creation/Evolution.
![]()
|
Outros Links:
|
1. Introdução
A maioria dos cientistas considera as evidências para a evolução como esmagadoras. Assim, convencidos de que a evolução já foi minuciosamente e suficientemente documentada, às vezes falham em considerar como novas descobertas podem fornecer evidências para a evolução que possam ser poderosamente persuasivas para indivíduos inclinados para crenças criacionistas. Neste artigo, descrevo algumas descobertas do meu próprio campo da genética molecular, descobertas cujas implicações para o debate criação-evolução não foram explicitamente discutidas quando foram relatadas. Tento mostrar como elas fornecem evidências para a evolução que são tanto convincentes quanto conceitualmente simples o suficiente para que o leigo interessado as aprecie.
A nova evidência molecular refere-se a uma questão que, na minha opinião, representa um dos poucos casos em que um argumento criacionista demonstrou consistência lógica e levou a posição evolutiva a um impasse. Esta é a questão de como interpretar as semelhanças entre as espécies vivas modernas, especialmente as semelhanças observadas ao nível molecular. Como veremos, as recentes descobertas da genética molecular resolvem este impasse inequivocamente a favor da evolução.
1.1 A visão evolutiva das semelhanças entre espécies
Primeiro, considere como os evolucionistas interpretam as semelhanças entre espécies vivas hoje. Humanos atuais e chimpanzés, apesar das óbvias diferenças externas e comportamentais, possuem órgãos internos extremamente semelhantes e funções fisiológicas; de fato, seus genes são mais de 98% idênticos (Goodman et al., J Molec Evolution 30:260,1990). Assim como a semelhança entre dois irmãos sugere uma parentalidade comum, a semelhança entre espécies sugere ancestrais comuns. Os evolucionistas acreditam que humanos, gorilas e chimpanzés evoluíram de um ancestral comum: uma criatura semelhante a um macaco que viveu talvez entre cinco e dez milhões de anos atrás, relativamente recentemente na escala de tempo geológico. (A ideia de que humanos e macacos podem compartilhar um ancestral comum parece particularmente inaceitável para os criacionistas devido às implicações teológicas de tal relação e à clara contradição com a interpretação literal dos criacionistas do Gênesis bíblico.) Espécies menos semelhantes aos humanos do que os macacos — como, por exemplo, ratos — são acreditadas ter se separado milhões de anos antes de um ancestral mamífero primitivo comum. Diagramas da árvore genealógica evolutiva que expressam tais relações entre espécies foram construídos por biólogos evolucionistas analisando as semelhanças de organismos atuais. Em muitos casos, restos fossilizados de espécies extintas podem ser usados para apoiar as características de tais árvores evolutivas; no entanto, a evidência fóssil não será discutida neste artigo.
Outra fonte extensiva de dados que tem sido de grande importância na construção de diagramas de árvores de similaridade é a comparação de proteínas e genes entre espécies. As proteínas são grandes moléculas biológicas formadas por subunidades chamadas aminoácidos, que estão ligados uns aos outros em cadeias, como os vagões de um trem. Existem vinte tipos diferentes de aminoácidos usados nas proteínas, e a maioria das proteínas contém centenas dessas subunidades. Cada proteína tem um número específico e uma sequência de aminoácidos, e essa sequência determina quais propriedades aquela proteína terá. Para que uma célula sintetize uma proteína específica, ela deve acessar um "banco de informações" no qual as sequências de aminoácidos são armazenadas; esse banco de informações é composto pelos genes do organismo, que contêm as sequências de aminoácidos codificadas em moléculas de ácido desoxirribonucleico (DNA). Os bioquímicos podem purificar proteínas e aprender a sequência exata de seus aminoácidos, ou podem obter essas informações lendo a sequência apropriada do DNA de um organismo. Um esforço considerável tem sido dedicado à comparação das sequências de proteínas semelhantes isoladas de diferentes espécies. Por exemplo, uma proteína chamada "citocromo c" tem sido examinada em mais de oitenta espécies. Essas sequências de aminoácidos do citocromo c representam bits de dados "digitais" que podem ser usados para quantificar diferenças entre espécies, e essas diferenças podem ser usadas para construir árvores evolutivas muito semelhantes às baseadas em comparações de características "analógicas" da anatomia corporal. Essas árvores de sequências de proteínas — bem como árvores baseadas em similaridades de estrutura de DNA — concordam notavelmente bem com as árvores evolutivas derivadas anteriormente de similaridades anatômicas. A concordância de árvores evolutivas construídas a partir de tipos completamente diferentes de dados (por exemplo, Goodman et al Mol Phylogenet Evol 9:585, 1998) tem sido tomada pelos evolucionistas como evidência da validade do quadro intelectual no qual as árvores se baseiam: a teoria da evolução (ver Jukes, em Scientists Confront Creationism, editado por Godfrey, WW Norton, Nova York 1983; Creation/Evolution XVIII:42, 1986; Goodman et al., J Mol Evol 30: 260, 1990).
1.2 A visão criacionista sobre as semelhanças entre espécies leva a um impasse
Contudo, os criacionistas têm uma interpretação alternativa das semelhanças nas sequências de aminoácidos refletidas nas árvores dos evolucionistas. Eles afirmam que tais semelhanças nas sequências em espécies "relacionadas" simplesmente refletem a escolha do criador de projetar espécies semelhantes para funcionar de maneira similar, não apenas no nível de ossos, músculos e órgãos, mas também no nível da função proteica — daí as semelhanças nas sequências de aminoácidos.
Assim, as semelhanças entre espécies em anatomia e estrutura proteica podem ser interpretadas de duas maneiras inteiramente diferentes. Os evolucionistas dizem que a semelhança entre características de, por exemplo, humanos e primatas reflete o fato de que essas características foram herdadas de um ancestral comum; isto é, as características semelhantes de humanos e primatas são determinadas por cópias modernas de genes que uma vez existiram em uma espécie que era ancestral tanto para os primatas quanto para os humanos. Os criacionistas dizem que primatas e humanos foram criados independentemente, mas foram projetados com características semelhantes para que funcionassem de maneira similar. Tanto a visão de cópia gênica quanto a de criação independente parecem consistentes com os dados de semelhança, mas qual visão está correta?
1.3 Uma possível justificativa para resolver o impasse
Uma maneira de distinguir entre cópia e criação independente é sugerida por analogia com os seguintes dois casos da literatura jurídica. Em 1941, o autor de um livro de química entrou com uma ação alegando que partes de seu livro haviam sido plagiadas pelo autor de um livro concorrente (Colonial Book Co, Inc. v. Amsco School Publications, Inc., 41 F. Supp.156 (S.D.N.Y. 1941), aff'd 142 F.2d 362 (2nd Cir. 1944)). Em 1946, o editor de um diretório comercial para a indústria da construção fez acusações semelhantes contra um editor de diretório concorrente (Sub-Contractors Register, Inc. v McGovern's Contractors & Builders Manual, Inc. 69 F.Supp. 507, 509 (S.D.N.Y. 1946)). Em ambos os casos, a mera semelhança entre o conteúdo das cópias alegadas e os originais não foi considerada evidência convincente de cópia. Afinal, ambos os livros de química estavam descrevendo o mesmo corpo de conhecimento químico (os livros foram projetados para "funcionar de maneira semelhante") e ambos os diretórios listavam membros da mesma indústria, de modo que uma semelhança substancial seria esperada mesmo que não tivesse ocorrido cópia. No entanto, em ambos os casos, erros presentes nos "originais" apareceram nas cópias alegadas. Os tribunais julgaram que era inconcebível que os mesmos erros pudessem ter sido cometidos independentemente por cada autor e réu, e decidiram em ambos os casos que havia ocorrido cópia. O princípio de que erros duplicados implicam cópia está agora bem estabelecido no direito autoral. (Em reconhecimento a este fato, editores de diretórios incluem rotineiramente entradas falsas em seus diretórios para pegar plagiadores potenciais.)
Os "erros" nas espécies modernas podem ser usados como evidência de "cópia" de ancestrais antigos? Na verdade, a resposta para esta questão parece ser "sim", já que investigações recentes em genética molecular descobriram alguns exemplos dos mesmos "erros" presentes no material genético de humanos e primatas. Para compreender essas descobertas, é necessário saber um pouco sobre o DNA, a molécula química na qual a informação genética é armazenada.
2.1 Fundamentos do DNA
Em um aspecto, a estrutura básica do DNA assemelha-se à dos proteínas: ambos são feitos de cadeias lineares de subunidades variadas. Além desta característica comum, a estrutura do DNA é bastante diferente da dos proteínas. As subunidades no DNA são chamadas de nucleotídeos ou bases, e a sequência desses nucleotídeos contém a informação genética que especifica a sequência de aminoácidos em cada proteína feita pelo organismo. Enquanto 20 aminoácidos diferentes compõem as subunidades das proteínas, existem apenas quatro bases nucleotídicas diferentes no DNA, geralmente abreviadas como A, T, G e C. De acordo com o "código genético" deduzido por cientistas na década de 1960, cada aminoácido é especificado por um ou mais tripletos de nucleotídeos; por exemplo, a sequência GCG especifica o aminoácido alanina. Como existem 64 tripletos diferentes (cada um chamado de códon) e apenas 20 aminoácidos para especificar, alguns aminoácidos são representados por mais de um triplo (por exemplo, ATA, ATC e ATT codificam todos o aminoácido isoleucina); e três tripletos — TAA, TAG e TGA — representam "códon de parada" que marcam o fim da sequência do gene que pode ser usada para especificar a sequência de aminoácidos.
|
|
|
Figura 1. Fundamentos do DNA. O óvalo central representa uma célula, dentro da qual se encontra o núcleo. Dentro do núcleo, a maior parte do DNA existe como uma hélice dupla. O óvalo no canto superior esquerdo mostra uma visão ampliada do DNA, na qual as hélices foram desenhadas "desenroladas" para revelar a semelhança com uma escada. As informações genéticas são armazenadas nas sequências de bases nucleotídicas (A, T, G ou C) que formam os degraus da escada. Cada degrau é formado por um par de bases nucleotídicas em contato, uma base anexada ao esqueleto de uma fita e a outra anexada ao esqueleto da outra fita. Um nucleotídeo "A" sempre se emparelha com um "T," e um "G" sempre se emparelha com um "C." Para sintetizar uma proteína, a célula lê as informações genéticas do gene para aquela proteína ao "transcrever" uma molécula de RNA a partir do gene. Para a transcrição, as fitas da hélice dupla do DNA devem separar-se parcialmente para que as bases que formam o RNA possam se montar de acordo com as regras de emparelhamento complementar de bases. A visão ampliada no canto superior direito mostra as duas principais diferenças entre RNA e DNA: a fita do esqueleto do RNA tem uma estrutura química ligeiramente diferente (representada pela linha tracejada), e uma forma ligeiramente modificada de "T" conhecida como "U" é encontrada no RNA. A fita transcrita de RNA atua como um "mensageiro" que transporta as informações genéticas do armazenamento no núcleo para os módulos de fabricação de proteínas (representados na figura por óvalos cinza duplo) no citoplasma. A visão ampliada no canto inferior esquerdo mostra que a sequência de bases de RNA é lida de modo que cada tríade de bases especifica um aminoácido (aa1, aa2, etc.) na proteína. A proteína dobra-se em uma estrutura tridimensional funcional que depende da sequência linear de aminoácidos. |

O DNA contém duas cadeias lineares em uma estrutura de dupla hélice que se assemelha a uma escada torcida -- a famosa "dupla hélice". Os trilhos verticais da escada representam uma cadeia de esqueleto uniforme que não contém informações de sequência. Como mostrado na Figura 1 acima, a informação é armazenada nos "degraus" da escada, que são formados por um par de bases nucleotídicas, cada uma projetando-se de uma fita do esqueleto vertical e tocando a base da fita oposta para formar um "degrau". A base G em uma fita sempre entra em contato com uma base C na fita oposta; da mesma forma, um A sempre entra em contato com um T. Assim, uma sequência de Ts em uma fita pode "emparelhar bases" ou "anilar" com uma fita contendo uma sequência de As para formar uma estrutura de dupla fita. A sequência de bases nucleotídicas em uma fita é dita ser "complementar" à sequência da outra fita. Para qualquer gene, os tripletos de bases que codificam a sequência de aminoácidos estão apenas em uma fita. Alguns genes são codificados em uma fita, enquanto outros genes estão na outra fita. Na maioria dos genes de mamíferos, o DNA que codifica as sequências de aminoácidos é interrompido por segmentos de DNA aparentemente sem significado ("introns"). As sequências de introns precisam ser removidas antes que a sequência seja usada para montar aminoácidos; essa remoção, ou splicing, não ocorre na molécula de DNA, mas na próxima etapa de transferência de informação.
Para que uma célula produza uma proteína específica, cuja sequência de aminoácidos está codificada em um gene, as informações da sequência no DNA devem primeiro ser copiadas ou "transcritas" em uma molécula de fita simples chamada ácido ribonucleico (RNA), conforme mostrado acima na Figura 1. Este transcrito inicial de RNA sofre várias alterações estruturais, conhecidas coletivamente como "processamento", antes de ser usado para montar aminoácidos. Essas etapas de processamento incluem o "splicing" de segmentos intrônicos desnecessários do RNA e a adição de nucleotídeos em uma extremidade -- a "cauda poli(A)" -- que promovem o funcionamento adequado do RNA na célula. É o RNA "processado" que participa diretamente da montagem de aminoácidos em proteínas. A transcrição de um gene em uma cópia de RNA é muito rigidamente controlada, em parte por sequências regulatórias altamente específicas conhecidas como promotores, que para a maioria dos genes ocorrem no DNA logo fora da região transcrita, mas próximas à posição onde a transcrição em RNA deve começar.
Quando uma célula se divide, toda a sequência do seu DNA deve ser duplicada em duas cópias fiéis do original; uma cópia vai para cada uma das células "filhas" criadas pela divisão. Ocasionalmente, ocorrem erros neste mecanismo de cópia, criando "mutações" na sequência do DNA. Existem vários tipos de mutações, incluindo substituições de um ou poucos nucleotídeos, deleções de nucleotídeos, duplicação de segmentos de DNA ou inserção de segmentos de DNA estranhos em uma sequência de DNA não relacionada. Tais alterações podem ocorrer na maioria das células do corpo — fígado, pele, músculo, etc. — sem serem transmitidas à prole quando o organismo se reproduz. No entanto, quando as mutações ocorrem no óvulo ou no espermatozoide ou, mais geralmente, em "células germinativas" (ou seja, o óvulo ou o espermatozoide mais seus precursores embriológicos), elas podem ser transmitidas às gerações futuras. Frequentemente, as mutações são inconsequentes: por exemplo, podem cair fora de um gene, ou se estiverem dentro de um gene, podem não alterar o aminoácido codificado. Muitas diferenças genéticas entre espécies estreitamente relacionadas são consideradas representar tais mutações aleatórias e inconsequentes. Às vezes, no entanto, as mutações danificam criticamente a função de um gene. De fato, tais mutações são a causa de doenças genéticas como fibrose cística, anemia falciforme, fenilcetonúria e centenas de outras, bem como muitas aberrações genéticas estudadas em animais de laboratório. Quando geneticistas moleculares examinam o DNA de pacientes com tais doenças bem caracterizadas, eles quase sempre podem encontrar o gene defeituoso e identificar a mutação que o inativou, já que é raro que uma doença genética seja causada por uma deleção que remova um gene inteiro. As mutações que causam doenças genéticas e malformações são geralmente tão prejudiciais à sobrevivência e ao sucesso reprodutivo do organismo que na natureza — ou seja, na ausência da ciência médica moderna — tenderiam a ser "eliminadas" pela pressão da seleção natural. Raramente, as mutações podem ser benéficas para um organismo: esses casos raros formam a base para adaptações evolutivas que melhoram o "fitness" de um organismo ao seu ambiente.
2.2 Erros no DNA
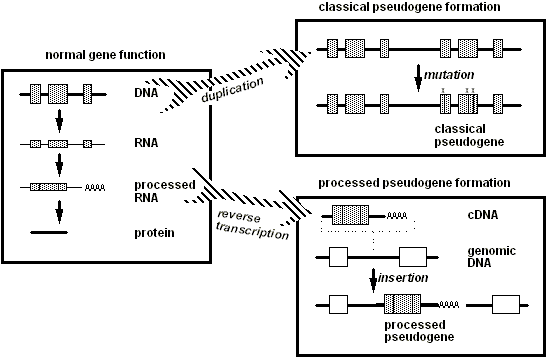
A tecnologia de DNA recombinante permitiu, nos últimos anos, que os cientistas determinassem a sequência de nucleotídeos em segmentos de DNA de muitas espécies, e acumularam-se várias bilhões de nucleotídeos de informações. Essas sequências aumentaram enormemente nossa compreensão de como os genes funcionam normalmente; mas, mais ao ponto deste artigo, elas forneceram um tesouro de "erros" genéticos que são pistas potenciais para a análise da cópia discutida anteriormente. Neste contexto, uso a palavra "erro" para incluir qualquer característica de DNA que tenhamos bons motivos para acreditar que (1) originou-se de um "acidente" genético; (2) não serve de benefício ao organismo que carrega as características; e (3) portanto, não pode razoavelmente ser interpretado como tendo sido "desenhado." Discutirei várias classes sobrepostas desses "erros", que argumentam a favor da evolução de maneiras ligeiramente diferentes. Uma classe inclui "genes-fantasma", ou cópias não funcionais danificadas de genes. Discutirei três classes de genes-fantasma, a última das quais se sobrepõe a outra categoria maior de "erros" genéticos conhecida como retrotransposons, que também será discutida. Veja a Figura 2.
|
|
|
Figura 2. Este diagrama de Venn ilustra as classes de "erros" discutidas nesta postagem, exceto que a classe de "pseudogenes unitários" (que é realmente um subconjunto minúsculo de "pseudogenes clássicos") não é mostrada no diagrama. Os pseudogenes processados representam a interseção do conjunto de pseudogenes e do conjunto de retrotransposons. |

2.2.1 Pseudogenes
a. Pseudogenes unitários.
Coelhos-da-índia e primatas, incluindo humanos, adoecem a menos que consumam ácido ascórbico em sua dieta. Para humanos e coelhos-da-índia, o ácido ascórbico é, portanto, uma vitamina (vitamina C), enquanto a maioria das outras espécies pode sintetizar seu próprio ácido ascórbico e, portanto, não requer essa molécula em sua dieta. A razão pela qual humanos e coelhos-da-índia não podem fabricar seu próprio ácido ascórbico é que eles carecem de um gene funcional que codifica a enzima proteica conhecida como L-gulono-gama-lactona oxidase (GLO), que é necessária para sintetizar ácido ascórbico. Na maioria dos mamíferos, genes funcionais de GLO estão presentes, herdados - de acordo com a hipótese evolutiva - de um gene funcional de GLO em um ancestro comum dos mamíferos. De acordo com essa visão, cópias do gene GLO nas linhagens de humanos e coelhos-da-índia foram inativadas por mutações. Presumivelmente, isso ocorreu separadamente em ancestrais de coelhos-da-índia e primatas cujas dietas naturais eram tão ricas em ácido ascórbico que a ausência de atividade da enzima GLO não era uma desvantagem – não causava pressão seletiva contra o gene defeituoso.
Geneticistas moleculares que analisam sequências de DNA sob uma perspectiva evolutiva sabem que grandes deleções gênicas são raras, por isso os cientistas esperavam que cópias mutantes não funcionais do gene GLO --conhecidas como "pseudogenes"-- ainda estivessem presentes em primatas e porcos-da-índia como relíquias do ancestral funcional do gene. Em contraste, os criacionistas acreditam que humanos e porcos-da-índia foram criados independentemente de todas as outras espécies e devem ter sido "desenhados" para funcionar sem o GLO. Se isso fosse verdade, não se esperaria que essas duas espécies carregassem uma cópia defeituosa do gene GLO. Na verdade, pseudogenes GLO foram detectados tanto em porcos-da-índia quanto em humanos (Nishikimi et al. J Biol Chem 267: 21967, 1992; Nishikimi et al. J Biol Chem 269:13685, 1994), consistente com a visão evolutiva; presumivelmente, pseudogenes relacionados também existem em primatas não humanos que requerem vitamina C na dieta. Os tipos de mutações encontrados nos pseudogenes humanos e de porco-da-índia são típicos das observadas em doenças genéticas, como as mencionadas anteriormente. Neste ensaio, chamo as sequências de DNA GLO humanas e de porco-da-índia de "pseudogenes unitários" para distingui-las de dois outros tipos de pseudogene que ocorrem em uma espécie que também possui uma cópia funcional do mesmo gene (veja abaixo). Os leitores devem notar que o termo "pseudogene unitário" é usado aqui por conveniência; não há nomenclatura padrão para descrever este tipo raro de pseudogene.
Pseudogenes unitários são relativamente raros; cada um é como um defeito genético que afeta todos os indivíduos de uma espécie. Mas esses genes defeituosos não correspondem a doenças genéticas porque, se causassem sintomas significativos ou outras desvantagens para seus proprietários, indivíduos com genes intactos teriam vencido a competição por sobrevivência e reprodução há muito tempo, assim eliminando o pseudogene da existência. De uma perspectiva evolutiva, os pseudogenes unitários representam relíquias genéticas de genes cuja função era importante em espécies ancestrais, mas se tornaram desnecessárias na espécie moderna; ou seja, são sequências de DNA vestigiais. A presença de relíquias de pseudogenes não funcionais é facilmente explicada pelo modelo evolutivo: são uma consequência natural de mutações que não são eliminadas pela seleção natural porque a função do produto do gene se tornou desnecessária. De fato, este modelo prevê que muitos pseudogenes unitários deveriam ser encontrados se os cientistas examinarem os genes que especificam estruturas vestigiais — por exemplo, genes que codificam estruturas oculares em espécies cegas, como as toupeiras ou habitantes de cavernas. (Um exemplo confirmando esta previsão foi recentemente descrito em toupeiras marsupiais: um aparente pseudogene unitário relacionado ao gene da proteína de ligação de retinoides interfotorreceptora [Springer et al., PNAS 94:13754, 1997]. Um exemplo conceitualmente similar no DNA humano é fornecido por sequências de DNA de receptores odorantes: cerca de 70% dessas sequências são pseudogenes, refletindo o status quase vestigial de nossa percepção olfativa em comparação com a de outras espécies [Rouquier et al., Nat Genet 18:243,1998; Rouquier, et al. Human Molec Genet &:1337,1998; Sharon et al., Genomics 61:24,1999; Rouquier et al., PNAS 97:2871,2000; Glusman et al, Genome Res 11:685, 2001].) Em contraste, tais pseudogenes não seriam esperados se cada espécie fosse criada independentemente por um designer inteligente (a menos que esse designer estivesse intencionalmente simulando a evolução). Vários outros pseudogenes unitários são conhecidos em humanos, incluindo sequências homólogas [ou seja, semelhantes e consideradas derivadas de um ancestral comum] aos genes que codificam a urato oxidase (Yeldandi et al, Gene 109:2821, 1994; Wu et al, J Mol Evol 34:78, 1992), a alfa-1,3-galactosiltransferase (Galili e Swanson, PNAS 88:7401,1991) e a proteína de superfície RT6, uma ADP-ribosiltransferase ligada por glicofosfatidilinositol (Haag et al, J Mol Biol 243:537,1994). Mais podem ser descobertos à medida que o Projeto Genoma Humano avança o conhecimento de nossa sequência de DNA.
(Outro grupo interessante de pseudogenes unitários são sequências polimórficas que são genes em alguns indivíduos e pseudogenes em outros, com frequências diferentes de pseudogenes em várias populações. Exemplos incluem genes humanos para o receptor de quimiocina CCR5, para a alpha2-fucosiltransferase Se, para os citocromos p450 2C19 e p450 2D6, para a enzima tiopurina metiltransferase e para a lipoproteína apo(a). Para estes exemplos, a ausência das proteínas funcionais correspondentes é, na maioria das vezes, sem consequências, mas pode tornar-se clinicamente importante — seja benéfica ou prejudicial — em certas circunstâncias ambientais ou em combinação com outros genes. Em alguns casos, o mesmo produto gênico pode ser benéfico em algumas circunstâncias e prejudicial em outras, de modo que a seleção leva a uma frequência gênica intermediária.)
b. Pseudogenes duplicados clássicos
Uma classe muito maior de pseudogenes aparentemente surge de acidentes em um padrão de alteração gênica que tem sido importante na evolução de genes funcionais normais: o padrão de duplicação e diferenciação (Ohta, Genome 31:304,1989; Holland et al., Dev Suppl 36:125, 1994). Este padrão é evidente a partir da observação frequente (em DNA de uma variedade de espécies) de blocos de sequências que aparentemente foram duplicados de modo que duas ou mais repetições de sequências similares aparecem lado a lado, ou seja, em tandem (veja caixa 1).
Presumivelmente, imediatamente após a duplicação, cada cópia do gene tinha uma sequência idêntica. (Veja a Figura 3.) Mas, conforme as sequências de DNA são copiadas de geração em geração, mutações podem acumular-se independentemente nas cópias da sequência duplicada, com várias consequências possíveis.
|
|
|
Figura 3. Na função normal do gene (painel esquerdo), o DNA é transcrito em RNA, que é então "processado" pela remoção de íntrons (as sequências não codificantes entre as caixas cinzas) e adição de uma cauda poli(A). O RNA processado maduro é então traduzido em uma cadeia de aminoácidos para formar uma proteína. Os painéis à direita ilustram os dois caminhos que geram o pseudogene duplicado clássico (topo) e o pseudogene processado (fundo). No caminho superior, a duplicação do DNA gera duas cópias do gene inteiro (caixa superior direita), mas mutações em uma cópia (representadas pelos "x"s) a tornam um pseudogene. No outro caminho, um transcrito de RNA processado de um gene pode ser transcrito reversamente em uma cópia de cDNA (caixa inferior direita) que se insere de volta no DNA da célula em uma posição aleatória no genoma, geralmente – como mostrado aqui – no DNA espaçador entre genes (caixas brancas na Figura). |
i. Algumas mutações podem não ter efeito sobre o funcionamento do gene.
| CAIXA 1 |
|---|
|
Os criacionistas argumentam comumente que as características que observamos no DNA das espécies modernas — presumivelmente incluindo sequências repetidas tandemicamente — foram projetadas especificamente por um criador inteligente; enquanto os cientistas veem as sequências de repetição tandemica como resultado de duplicações acidentais de DNA. Um argumento a favor da visão científica é que podemos ver exemplos de tais acidentes genéticos ocorrendo hoje no DNA humano (assim como no DNA de espécies de laboratório) sem aparente intervenção divina. Devido ao viés de detecção — isto é, encontramos coisas apenas onde procuramos por elas — os melhores exemplos estudados de duplicações em humanos são aqueles que causam doenças. Uma maneira pelas quais as duplicações de DNA podem causar doenças é se apenas parte de um gene for duplicada, de modo que a proteína resultante teria alguns aminoácidos repetidos, alterando assim a estrutura e a função da proteína (Heikkinen et al., Am J Hum Genet 60:48, 1997; Hu e Worton Hum Mutat 1:3, 1992). Quando as duplicações de DNA ocorrem em células somáticas (ou seja, fora da linhagem celular que contribui para óvulos e espermatozoides), elas não podem ser transmitidas às gerações futuras, mas podem causar problemas para o indivíduo afetado; por exemplo, foram relatados casos de câncer contendo duplicação parcial de genes nas células cancerosas, enquanto a duplicação está ausente nos tecidos normais do corpo (Schichman et al., Cancer Research 54: 4277, 1994), indicando que a duplicação ocorreu durante a vida do paciente afetado. Duplicações grandes envolvendo genes inteiros podem criar problemas clínicos se cópias extras de um gene funcional inteiro puderem produzir efeitos prejudiciais; embora isso seja incomum, um exemplo bem estudado é a doença neurológica Charcot-Marie-Tooth tipo 1A, na qual uma cópia extra do gene conhecido como PMP-22 parece ser o culpado. Foram relatados numerosos casos de CMT1A onde a duplicação está presente no paciente afetado, mas não em nenhum dos pais do paciente, indicando que a duplicação deve ter ocorrido nas células germinativas de um dos pais ou muito cedo no desenvolvimento embrionário do paciente (Eur Neurol 34:135, 1994). Estes exemplos tornam claro que a duplicação de genes não é apenas uma construção hipotética — invocada para explicar repetições tandemicas que foram criadas por eventos inescrutáveis no distante passado — mas sim um processo bioquímico natural que pode ser observado hoje em humanos (também pode ser estudado em espécies de laboratório tão diversas quanto bactérias e moscas-da-fruta; Lupski et al. Am J Hum Genet 58:21, 1996). Genomas de vertebrados modernos podem refletir evidências de dois eventos antigos de duplicação em todo o genoma que dobraram todo o conteúdo gênico (Sidow Curr Opin Genet & Devel 6:715,1996; Endo et al, Gene 205:19, 1997; Pebusque et al. Mol Biol Evol:1145, 1998); dobramentos semelhantes mais recentes foram deduzidos em certas plantas, sapos e até ratos (Gallardo et al, Nature 401:341, 1999). |
ii. Outras mutações podem levar a uma proteína que tem uma função ligeiramente diferente daquela do gene original. De fato, tal diferenciação de genes duplicados para desenvolver novas funções em uma cópia aparentemente explica uma parte significativa da expansão na complexidade dos genes de organismos superiores. Por exemplo, pensa-se que o gene para uma proteína primordial transportadora de oxigênio tenha se duplicado, levando a genes separados que codificam mioglobina (a proteína transportadora de oxigênio do músculo) e hemoglobina (a proteína transportadora de oxigênio dos glóbulos vermelhos). Em seguida, o gene da hemoglobina duplicou-se, e as cópias diferenciaram-se nas formas conhecidas como ![]() e
e ![]() . Mais tarde, tanto o gene da hemoglobina
. Mais tarde, tanto o gene da hemoglobina ![]() quanto o gene da hemoglobina
quanto o gene da hemoglobina ![]() duplicaram-se várias vezes, produzindo um grupo de sequências relacionadas à hemoglobina-
duplicaram-se várias vezes, produzindo um grupo de sequências relacionadas à hemoglobina-![]() e um grupo de sequências relacionadas à hemoglobina-
e um grupo de sequências relacionadas à hemoglobina-![]() . Os grupos incluem genes funcionais que são ligeiramente diferentes, que são expressos em momentos diferentes durante o desenvolvimento do embrião ao adulto, e que codificam proteínas especificamente adaptadas a esses períodos de desenvolvimento. A divergência entre a mioglobina e os genes
. Os grupos incluem genes funcionais que são ligeiramente diferentes, que são expressos em momentos diferentes durante o desenvolvimento do embrião ao adulto, e que codificam proteínas especificamente adaptadas a esses períodos de desenvolvimento. A divergência entre a mioglobina e os genes ![]() e
e ![]() ocorreu tão há muito tempo na evolução que a reorganização de informações genéticas que ocasionalmente ocorre no DNA distribuiu esses genes para diferentes cromossomos. Os genes dentro do grupo
ocorreu tão há muito tempo na evolução que a reorganização de informações genéticas que ocasionalmente ocorre no DNA distribuiu esses genes para diferentes cromossomos. Os genes dentro do grupo ![]() e do grupo
e do grupo ![]() duplicaram-se mais recentemente na evolução e ainda estão agrupados.
duplicaram-se mais recentemente na evolução e ainda estão agrupados.
iii. Finalmente, outras mutações ainda que alterem aminoácidos críticos, que afetem o splicing de íntrons ou que criem novos códons de parada, podem destruir completamente a função de uma sequência de gene duplicado e torná-lo um pseudogene; de fato, este é o destino da maioria das duplicações gênicas (Lynch e Conery, Science 290:1151, 2000). Os tipos de mutações que destroem a função do gene assemelham-se novamente a aquelas que desativaram genes não duplicados cruciais, causando assim doenças genéticas. Genes defeituosos que não são duplicados tendem a desaparecer das populações ao longo do tempo porque indivíduos que carecem de uma cópia funcional do gene são menos capazes de sobreviver para produzir descendentes (a menos que o gene não seja mais necessário, como nos pseudogenes unitários). No entanto, quando um gene defeituoso existe ao lado de uma cópia duplicada normal, a função contínua do gene normal geralmente compensa quaisquer mutações na cópia defeituosa; a sequência defeituosa é geralmente inofensiva e pode ser perpetuada no DNA como um pseudogene "duplicado clássico". Em geral, cada pseudogene deste tipo contém uma sequência que se assemelha ao gene inteiro — incluindo tanto as sequências regulatórias que se encontram fora das sequências de codificação de aminoácidos, quanto os íntrons que interrompem as sequências de codificação (veja acima). Diversos pseudogenes deste tipo foram encontrados no DNA de uma variedade de organismos, incluindo humanos. Por exemplo, tanto os clusters alfa quanto beta de genes de hemoglobina em humanos incluem pseudogenes duplicados deste tipo.
Embora a maioria dos pseudogenes "clássicos" esteja próxima ao gene do qual originaram-se por duplicação em tandem, recentemente vários laboratórios descreveram uma variedade peculiar de pseudogenes duplicados localizados perto dos centrômeros de vários cromossomos diferentes. (Os centrômeros são os segmentos cromossômicos onde — logo antes da divisão celular — as duas cópias duplicadas de cromossomos em forma de hot-dog parecem estar ligadas, conforme diagramado na Figura 4, abaixo). Aparentemente, durante a evolução dos primatas, várias regiões de DNA passaram por um processo mal compreendido que distribuiu cópias imperfeitas para as regiões centrômeras de múltiplos cromossomos. Os genes nessas cópias incluem íntrons, mas em muitos casos estão truncados e geralmente possuem múltiplas mutações pontuais que os tornam pseudogenes não funcionais. Exemplos desses pseudogenes centrômeros incluem sequências relacionadas ao gene da adrenoleucodistrofia ALD (Eichler et al., Human Molec Genet 6:991, 1997), o gene transportador de creatina SLC6A8 (Eichler et al. Human Molec Genet 5:899, 1996), o gene da neurofibromatose NF1 (Human Molec Genet 6:9, 1997) e um gene chamado FRG1 próximo ao locus da distrofia muscular facioscapulohumeral (Grewal et al., Gene 227:79, 1999).
c. Pseudogenes processados
Uma classe inteiramente diferente de pseudogenes, conhecida como pseudogenes processados (veja a Figura 3, painel inferior direito), surge de inserções naturais de cópias extras de genes derivadas de transcritos de RNA. Três características dessas sequências sugerem derivação de RNA:
i. Cada sequência de pseudogene processado assemelha-se a um transcrito de RNA no sentido de que a semelhança do pseudogene ao seu "gene-fonte" estende-se desde o local de iniciação do RNA até o local de terminação do RNA, mas não inclui sequências que se encontram imediatamente fora da região transcrita, incluindo sequências reguladoras como promotores.
ii. Estes pseudogenes carecem de sequências de íntrons que normalmente são transcritas em RNA, mas são em seguida removidas do RNA antes que este seja utilizado para especificar a sequência de aminoácidos de uma proteína.
iii. Geralmente incluem a "cauda" poly(A) característica de transcritos de RNA que codificam proteínas.
Além disso, ao contrário dos pseudogenes duplicados clássicos, que geralmente são encontrados próximos ao gene funcional do qual derivaram por duplicação, os pseudogenes processados parecem ser inseridos no DNA em locais aleatórios. Essa aleatoriedade é o que se esperaria de uma molécula de RNA que pode flutuar livremente longe de seu gene de origem (do qual foi originalmente transcrito) antes que uma cópia seja reinserida de volta no DNA. Mesmo que codifique uma sequência correta de aminoácidos, um pseudogene processado é geralmente não funcional porque carece das sequências regulatórias (como um promotor transcricional) necessárias para a expressão gênica; como uma cópia extra não funcional, tal sequência pode acumular mutações aleatórias sem pressão seletiva, ou seja, sem reduzir o sucesso reprodutivo de um organismo que carrega tais mutações.
Os pseudogenes processados não devem ser confundidos com um pequeno número de cópias gênicas retropostas que são, na verdade, genes funcionais. Estes podem surgir porque, raramente, uma cópia de DNA de um RNA processado pode inserir-se no DNA de tal forma que a cópia inserida possa ser ativamente expressa. Nestes casos, a sequência de DNA pode reter a função e, portanto, permanecer sob pressão seletiva contra a acumulação de mutações. Embora tais sequências — que podem ser chamadas de genes processados ou genes retropostos — representem uma fração ínfima das cópias de genes retropostos observadas, mais de uma dúzia foram descobertas, especialmente como cópias gênicas expressas especificamente no testículo (Kleene et al, J Molec Evol 47: 275, 1998). Estes genes retropostos são facilmente distinguidos dos pseudogenes processados pela sua falta de mutações incapacitantes. O facto de estas poucas cópias de DNA retropostas serem genes úteis não sugere qualquer função para os muito mais numerosos pseudogenes processados com múltiplas mutações incapacitantes, como códon de parada, que impediriam a sua expressão como proteínas funcionais.
Os evolucionistas, já desde Darwin, apontaram estruturas vestigiais — como os olhos sem função de animais cegos que habitam cavernas ou os rudimentares ossos pélvicos de algumas cobras — como suporte à perspectiva evolutiva. Essas estruturas não servem a nenhuma função aparente que pudesse explicar seu desenho por um criador, mas podem ser facilmente compreendidas na perspectiva evolutiva como derivadas de estruturas que eram funcionais em espécies ancestrais. Sequências genéticas vestigiais — isto é, pseudogenes — fornecem exemplos exóticos de estruturas vestigiais e, portanto, evidências especialmente convincentes para a evolução. Tais sequências podem ser estudadas em uma variedade de espécies; sua relação com seu homólogo funcional é óbvia e quantitativa (com base no número de discrepâncias de sequência entre o gene e o pseudogene); e o subconjunto de pseudogenes processados pode — com raras e facilmente reconhecíveis exceções — ser assumido como totalmente sem função desde o momento de sua origem. Finalmente, os pseudogenes são uma fonte rica de dados porque são abundantes. A sequência recentemente concluída do cromossomo 22 humano (Dunham et al, Nature 402:489, 1999) identificou 134 pseudogenes juntamente com 545 genes na região sequenciada, o que corresponde a cerca de 1,1% do genoma humano. Se esta amostra for representativa, podemos esperar cerca de 15.000 pseudogenes no genoma humano.
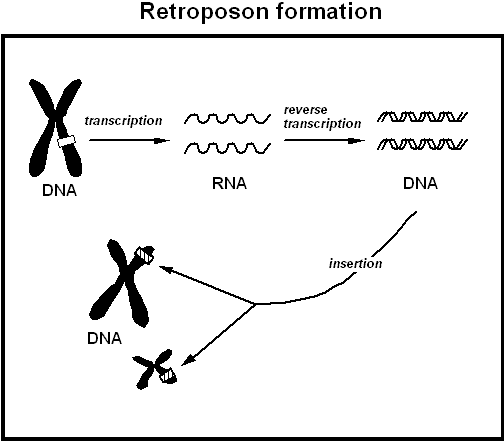
2.2.2 Retrotransposons
Como uma sequência de RNA processado pode voltar para o DNA? De fato, pseudogenes processados são membros de uma classe muito maior de sequências conhecidas como elementos retroposados, que aqui chamo de "retroposons", e que todos envolvem sequências de RNA que foram inseridas no DNA. Como discutido acima, na fisiologia molecular celular normal, a informação genética passa do DNA para o RNA para a proteína. Às vezes, no entanto, ocorre um acidente genético e o RNA é retrotranscrito em DNA ("retro" ou para trás, em relação à direção normal) e o DNA é depositado de volta (ou "retroposado") em alguma posição aleatória no DNA da célula. (Veja a Figura 4.) Alguns leitores podem reconhecer a retroposição como o mecanismo pelo qual retrovírus como o HIV -- o vírus da AIDS -- se escondem no DNA dos linfócitos T de pacientes com AIDS. Como no caso do HIV, um requisito crítico para toda retroposição é a atividade de uma enzima chamada transcriptase reversa (RT), que gera uma cópia de DNA da sequência de RNA. Não se conhece nenhum gene que codifique esta enzima presente no genoma humano, exceto em cópias associadas a elementos que sofrem retroposição. A enzima RT não tem função conhecida na fisiologia celular normal, embora pareça que uma variante especializada de transcriptase reversa está envolvida na manutenção dos telômeros, sequências repetitivas nas pontas dos cromossomos. Uma vez que uma cópia de DNA de um RNA foi sintetizada pela RT, este DNA pode ser inserido em quebras no DNA que ocorrem de vez em quando na célula e que normalmente são seladas por um complexo maquinário de enzimas de reparo do DNA requerido por todas as células. Tais quebras ocorrem frequentemente em posições ligeiramente diferentes nas duas fitas de DNA, produzindo "extremidades escalonadas"; sequências de retroposon inseridas entre tais extremidades são frequentemente flanqueadas em ambos os lados por sequências curtas idênticas criadas pelo reparo das duas extremidades escalonadas.
|
|
|
Figura 4. A formação de retroposons ocorre quando uma sequência de DNA é transcrita em RNA, que então é "retrotranscrito" de volta para DNA. No canto superior esquerdo, a Figura mostra um cromossomo como ele aparece logo antes da divisão celular, parecendo dois cachorros-quentes amarrados juntos no centrômero. Um gene em um determinado cromossomo pode dar origem a vários pseudogenes, que geralmente se inserem aleatoriamente em diferentes cromossomos. Um mecanismo similar espalha LINEs e SINEs, incluindo inserções Alu. |
Das muitas classes de retrotransposons conhecidas pelos biólogos moleculares, mencionarei quatro classes principais encontradas no DNA humano. (Para uma revisão recente, veja Prak e Kazazian, Nature Reviews, 1:134, 2000.)
a. Pseudogenes processados. Em geral, os pseudogenes processados (descritos acima) foram descobertos conforme os cientistas examinaram o genoma (usando técnicas além do escopo deste artigo) em busca de sequências semelhantes a genes conhecidos. Tais exames revelaram versões mutadas com as características "processadas" descritas acima, levando à sua identificação como retroposons. Como qualquer retroposon, esta classe poderia ter entrado no DNA da linhagem germinativa (ou seja, o DNA das células sexuais que permitem a propagação para futuras gerações) apenas se as células germinativas contivessem dois componentes: transcritos de RNA do gene e transcriptase reversa (RT) para copiá-lo de volta para DNA. Vamos considerar estes dois componentes por sua vez. Muitos dos melhores conhecidos proteínas são encontrados apenas em tecidos específicos diferenciados e não são expressos em outros lugares. Por exemplo, a hemoglobina é produzida apenas em células sanguíneas e seus precursores, e as proteínas pigmentos visuais são produzidas apenas no olho. Os genes para tais proteínas específicas de tecido raramente são transcritos em células germinativas, e, portanto, contribuem raramente para pseudogenes processados. Em contraste, todas as células possuem certas proteínas "de manutenção" necessárias para funções metabólicas básicas; transcritos de RNA que codificam essas proteínas estão presentes nas células germinativas e frequentemente contribuem para pseudogenes processados. O gene da gliceraldeído-3-fosfato desidrogenase, por exemplo, é um gene de manutenção representado por cerca de 10 pseudogenes processados no DNA humano (Ercolani et al, JBC 263:15335,1988). Como mencionado acima, as sequências de pseudogenes processados não incluem as sequências promotoras necessárias para a iniciação da transcrição de RNA; uma vez inseridas no DNA, esses pseudogenes geralmente não são transcritos e, portanto, não podem representar por si mesmos um gene-fonte para futuros retroposons. (Esta limitação contrasta com características de outras classes de retroposons, como veremos abaixo.) O outro componente necessário para a retroposição é a transcriptase reversa. A RT não está presente na maioria dos tecidos normais em quantidades mensuráveis, embora possa ser expressa se uma célula for infectada por um retrovírus que carrega o gene para esta enzima. Células germinativas, no entanto, são um tipo de célula no qual a atividade da RT pode ser encontrada na ausência de retrovírus infecciosos. Nessas células, a enzima aparentemente deriva de outros elementos de retroposon -- a serem discutidos abaixo -- que carregam genes funcionais de RT dentro de sua sequência.
b. SINEs. A melhor caracterizada classe de Elementos Espalhados Curtos (SINEs) em primatas são conhecidas como sequências Alu. Estas têm aproximadamente 300 pb de comprimento e não codificam nenhuma sequência proteica. A recente análise de sequências de DNA do genoma humano encontrou cerca de 1,1 milhão de Alus, compondo 10,6% do DNA (Nature 409:860, 2001). Diferentemente dos pseudogenes processados, que geralmente não são transcritos, as sequências Alu incluem um segmento que pode atuar como um promotor transcricional interno; assim, cada inserção Alu pode potencialmente ser transcrita em RNA, servindo como a fonte para uma nova inserção. Esta propriedade pode explicar parcialmente como essas sequências se tornaram tão abundantes em nossos genomas. No entanto, as evidências atuais sugerem que apenas um número muito pequeno de sequências Alu são fontes ativas de transcritos; talvez a transcrição da maioria das cópias seja inibida pelo ambiente cromossômico da inserção (Englander e Howard, JBC 270:10091, 1995). Mesmo que os transcritos de RNA Alu existam em algumas células germinativas, eles se re-inserem no DNA apenas raramente porque este passo requer transcriptase reversa, que pode não estar presente nas mesmas células onde o RNA Alu está sendo transcrito.
c. LINEs. Os Elementos Intercalados Longos (Long Interspersed Elements) representam uma família de sequências relacionadas que estão presentes em cerca de 868.000 cópias no nosso DNA, compondo cerca de 20% do nosso genoma (Nature 409:860, 2001). Eles diferem das sequências Alu por serem muito mais longos – até cerca de 7000 pares de bases – e por conterem duas sequências codificantes potenciais. Uma dessas sequências codificantes apresenta semelhança com genes RT ativos. Embora na maioria das cópias de LINE o gene RT contenha numerosas mutações que impediriam que ele codificasse qualquer enzima RT funcional, certas cópias de LINE codificam, de fato, transcriptase reversa ativa. Além disso, as regiões regulatórias logo fora das sequências codificantes dos LINEs causam a expressão dos genes seletivamente em células germinativas. Os LINEs possuem, assim, várias propriedades esperadas de sequências de DNA "egoístas" que podem se espalhar no DNA do hospedeiro simplesmente porque codificam sua própria maquinaria para se espalhar. Os LINEs podem ser expressos em células germinativas como RNA, e as raras cópias que codificam RT funcional podem permitir a transcrição reversa do RNA dos LINEs de volta para uma cópia de DNA, que pode então inserir-se em novas localizações no DNA da célula germinativa; quando tal célula amadurece para óvulo ou espermatozoide, a transmissão do novo LINE para futuras gerações pode ocorrer. Aparentemente, a RT frequentemente se desprende do RNA antes que a transcrição reversa esteja completa, já que a maioria das cópias de LINE está truncada em suas extremidades 5'. É possível que a atividade de transcriptase reversa codificada pelos LINEs também possa produzir cópias transcritas reversamente de outros RNAs – tais como transcritos Alu e transcritos de RNA de genes – que levam a novas inserções de sequências Alu e pseudogenes processados no DNA celular.
d. Retrovírus endógenos. Os retrovírus infecciosos foram descobertos como agentes de doenças humanas e têm sido intensivamente estudados. Eles são os elementos retroposadores mais complexos e podem ter evoluído a partir de elementos mais simples descritos acima. Todos contêm duas Repetições Terminais Longas (LTRs) não codificantes idênticas em suas extremidades, bem como três genes conhecidos como gag, pol e env. Estes genes são codificados no vírus não por DNA, mas por RNA. O gene pol codifica a transcriptase reversa e pode também codificar atividades enzimáticas adicionais. O gene env codifica proteínas que revestem a superfície externa (envoltório) do vírus infeccioso. O gene gag codifica proteínas adicionais necessárias para o processamento dos componentes virais. A estrutura comum a todos os retrovírus é, portanto, LTR-gag-pol-env-LTR. A LTR "esquerda" inclui sequências regulatórias que podem iniciar a transcrição de RNA para a direita, em direção ao gag-pol-env-LTR; a LTR "esquerda" é então recopiada da LTR "direita" por um mecanismo complexo. Os retrovírus infecciosos incluem o HTLV-I, que causa um tipo de leucemia em humanos, e o HIV, que causa a AIDS. Estes vírus tipicamente infectam tipos específicos de glóbulos brancos — linfócitos — e inserem cópias retrotranscritas de seus genes de RNA no DNA destas células. Logo após a descoberta dos retrovírus infecciosos, os cientistas notaram que sequências semelhantes estavam presentes no DNA de muitas espécies mamíferas, incluindo humanos; estas cópias são chamadas de retrovírus endógenos e presumivelmente representam as consequências de infecções retrovirais antigas de células germinativas. No DNA humano, existem cerca de 8 classes diferentes de retrovírus endógenos, com membros de cada classe variando em número de um ou dois a mais de 50 cópias. Essencialmente todos estes retrovírus endógenos contêm mutações que interromperiam a função de seus genes, como seria esperado se eles tivessem sido inseridos milhões de anos atrás sem pressão seletiva para manter a função dos genes. Além disso, as sequências duplicadas de LTR representam alvos potenciais para eventos de "recombinação homóloga" que deletam o DNA entre a região correspondente das LTRs, deixando apenas uma sequência composta de LTR; existem muitas mais cópias destes fragmentos de LTR isolados no DNA do que cópias de retrovírus completas.
3. Como erros antigos podem persistir em espécies modernas
Como cada um dos vários tipos de sequências não funcionais mencionados acima, surgindo em uma célula germinativa de um indivíduo particular, pode chegar a ser preservado em todos os indivíduos de uma espécie? Uma possibilidade é que cada uma dessas sequências tenha ocorrido por acaso próxima a um gene vantajoso que se tornou prevalente em uma população por seleção natural (o pseudogene ou retroposon "montou-se nas caudas" do gene vantajoso próximo; veja Nurminsky et al, Nature 396:572,1998; Nurminsky et al. Science 291:128, 2001). É possível que tais sequências não funcionais surjam com alta frequência e nós vejamos apenas aquelas poucas que são preservadas por tais influências indiretas ou por eventos de acaso em populações pequenas.
O ônus extra de carregar até mesmo uma grande sequência de pseudogene—por exemplo, 100.000 nucleotídeos—é insignificante para uma célula mamífera com aproximadamente três bilhões de nucleotídeos de informação. De qualquer forma, não existe nenhum mecanismo conhecido de "correção de prova" pelo qual a célula possa distinguir DNA não funcional de DNA funcional e eliminar seletivamente o que não precisa. Sequências de DNA sem função que cientistas inseriram no DNA de camundongos ou outras espécies são transmitidas fielmente aos descendentes, e pseudogenes e retrotransposons que ocorrem naturalmente parecem comportar-se de maneira semelhante. A acumulação de DNA sem função não é completamente desoposta; deleções de DNA ocorrem, mas aparentemente como acidentes raros que não discriminam entre sequências funcionais e não funcionais. Deleções que removem genes funcionais cruciais têm sido reconhecidas como causas raras de doenças genéticas; a menor aptidão dos indivíduos que as carregavam tenderia a eliminar cópias de DNA com tais deleções. Outras deleções que, por acaso, não removem nenhum gene funcional poderiam eliminar algum DNA inútil, incluindo pseudogenes e retrotransposons; mas um indivíduo com tal deleção não teria nenhuma vantagem seletiva particular como resultado da deleção, de modo que a propagação de cópias de DNA que carregam a deleção na população em geral não seria mais provável do que a propagação de qualquer outra mutação inconsequente. Assim, tais eventos de deleção são claramente um mecanismo ineficiente de "remoção de lixo"; e, como uma consequência inevitável dessa ineficiência, quantidades substanciais de sequências de "lixo" sem função acumularam-se entre os genes funcionais dos mamíferos. Esta é uma característica do material genético que não foi apreciada até que a tecnologia de DNA recombinante permitisse que biólogos moleculares olhassem além das sequências de aminoácidos para a estrutura do próprio DNA. Embora o alto conteúdo de "DNA lixo" tenha sido inicialmente surpreendente quando foi descoberto, nossa compreensão atual dos mecanismos de expansão do genoma (duplicação e inserção) e a aparente falta de pressão seletiva significativa para minimizar o tamanho do genoma combinam-se para tornar a acumulação de sequências inúteis no nosso DNA parecer inevitável.
4. O argumento do DNA para a evolução: pseudogenes compartilhados e retrotransposons
A observação crucial que relaciona a descoberta de pseudogenes e retroposons à teoria da evolução é esta: alguns pseudogenes e retroposons são compartilhados entre espécies diferentes, como se fossem copiados de um pseudogene ou retroposon em um ancestral comum. Vamos examinar exemplos de cada uma das classes de "erros" que discutimos acima.
| CAIXA 2 |
|---|
|
Os pseudogenes de galactosiltransferase compartilhados são fascinantes por uma razão que complica seu uso em argumentos contra criacionistas: as evidências sugerem que pode ter havido uma vantagem seletiva para mutações que inativaram esse gene. O produto enzimático do gene catalisa a produção de uma molécula de carboidrato específica que é encontrada nas membranas celulares de mamíferos que possuem a enzima, mas também em certas bactérias infecciosas. Indivíduos infectados com tais bactérias se beneficiariam ao montar um ataque imunológico contra essa molécula de carboidrato, mas se o mesmo carboidrato aparecesse em suas próprias células, tal ataque poderia danificar seus próprios tecidos. Portanto, indivíduos que carregam mutações na enzima -- e, portanto, não produziriam o carboidrato em suas próprias células -- estariam livres para montar um ataque imunológico focado nessa molécula, protegendo-os contra muitas bactérias sem o perigo de danificar seus próprios tecidos. Portanto, a pressão seletiva teria levado à propagação de cópias do gene que sofreram mutações desabilitadoras. Criacionistas poderiam razoavelmente argumentar que tais mutações poderiam ter ocorrido independentemente em diferentes espécies como exemplos de microevolução recente após a criação independente das espécies. É possível que diferentes mutações tenham, de fato, inativado o gene independentemente em vários ancestrais primatas. No entanto, os pseudogenes de galactosiltransferase do humano e do chimpanzé possuem mutações desabilitadoras idênticas; portanto, é mais provável que o gene tenha sido inativado em um ancestral comum humano/chimpanzé. |
4.1. Pseudogenes unitários compartilhados. Muitos dos pseudogenes unitários em humanos descritos anteriormente são compartilhados com outros primatas. Por "compartilhado" quero dizer mais do que simplesmente que o mesmo gene está inativo em duas espécies diferentes, já que essa situação poderia resultar se os genes correspondentes das duas espécies fossem inativados separadamente por mutações independentes. Em vez disso, em todos os exemplos que descrevo, os pseudogenes em primatas carregam muitas das mesmas mutações incapacitantes encontradas nos pseudogenes humanos correspondentes. Como mutações aleatórias independentes não seriam prováveis de serem idênticas em duas espécies diferentes, os pseudogenes idênticos e mutados são fortes evidências de que as mutações ocorreram em uma espécie ancestral comum.
Para o exemplo do pseudogene unitário GLO dos humanos, sabe-se que a vitamina C é necessária na dieta de outros primatas, (embora não para outros mamíferos, exceto os porcos- domésticos). A teoria da evolução faria a forte previsão de que os primatas também deveriam ser encontrados com pseudogenes GLO e que estes carregariam mutações debilitantes semelhantes às encontradas no pseudogene humano. Esta previsão foi enunciada em versões anteriores do presente ensaio. Um teste desta previsão foi recentemente relatado. Uma pequena seção da sequência do pseudogene GLO foi recentemente comparada entre humano, chimpanzé, macaco e orangotango; todos os quatro pseudogenes foram encontrados compartilhando uma deleção de nucleotídeo único comum que causaria que o restante da proteína fosse traduzido no quadro de leitura de tripletos incorreto (Ohta e Nishikimi BBA 1472:408, 1999).
O gene RT6 mencionado acima (2.2.1.a) codifica uma proteína de cerca de 230 aminoácidos expressa na membrana superficial dos linfócitos T de roedores; tanto o pseudogene humano quanto seu homólogo de chimpanzé contêm mutações que produzem os mesmos três códons de parada que impediriam a síntese de uma proteína RT6 (Haag et al, M Mol Biol 243:537,1994). Vários dos pseudogenes de receptores odorantes humanos mencionados acima são encontrados em outros primatas e compartilham as mesmas deficiências dos pseudogenes humanos (Rouquier S et al., Nat Genet18:243,1998; Rouquier S, et al. Human Molec Genet &:1337,1998; Sharon et al., Genomics 61:24,1999). O pseudogene do receptor NPY1 humano compartilha uma mutação de desvio de quadro crítica com homólogos de primatas (Matsumoto et al., J Biol Chem 271:27217, 1996). O pseudogene de urato oxidase humano compartilha três mutações incapacitantes com os pseudogenes de chimpanzé e orangotango (Wu et al, J Mol Evol 34:78, 1992). Além disso, o pseudogene de galactosiltransferase presente no genoma humano é compartilhado com grandes símios e macacos do Velho Mundo ( Galili e Swanson, PNAS 88:7401, 1991), embora a interpretação evolutiva desses pseudogenes de galactosiltransferase compartilhados seja complexa, pois pode ter havido pressão seletiva para inativar esta enzima (veja Caixa 2).
Em resumo, embora os pseudogenes unitários sejam relativamente raros em humanos, a maioria dos exemplos relatados é compartilhada com outros primatas não humanos.
(Os únicos outros exemplos de pseudogenes unitários humanos que conheço são exclusivos dos humanos, aparentemente tendo adquirido suas deficiências incapacitantes após a separação entre humanos e chimpanzés; portanto, são de interesse por potencialmente contribuírem para as diferenças fisiológicas entre essas duas espécies. Esses pseudogenes correspondem a uma queratina do tipo I do cabelo [Hum Genet 108:37, 2001], hidroxilase de ácido CMP-sialílico [Chou et al., PNAS 95:11751, 1998], monooxigenase contendo flavina-2 (FMO2) [J Biol Chem 273:30599, 1998], hidroxilase de ácido CMP-N-acetilneuramínico [Hayakawa et al., PNAS 98:11399, 2001] e o gene variável V10 do locus do receptor gama de células T humanas [Zhang et al., Immunogenetics 43:196, 1996]. Os leitores são convidados a informá-lo sobre pseudogenes unitários adicionais.)
4.2. Pseudogenes duplicados clássicos. Existem muitos exemplos de pseudogenes compartilhados deste tipo; descreverei apenas um. O gene da esteroide 21-hidroxilase codifica uma enzima envolvida no metabolismo de hormônios esteroides. No DNA humano, a sequência do gene da 21-hidroxilase, bem como um gene adjacente que codifica o "complemento C4", foi duplicada; ou seja, cópias quase idênticas de segmentos de DNA estão adjacentes umas às outras, cada cópia contendo um gene de complemento C4 e uma sequência de esteroide 21-hidroxilase. No entanto, apenas a cópia "B" do gene da 21-hidroxilase é funcional; a cópia "A" em todos os humanos é um pseudogene, ou seja, contém múltiplas mutações, incluindo uma deleção de 8 pb que impediria sua função. A sequência da cópia correspondente "A" do chimpanzé foi examinada; ela contém a mesma deletéria deleção de 8 pb observada no pseudogene humano (Kawaguchi, Am J Hum Genet 50:766-80, 1992).
Muitos dos pseudogenes centrômeros peculiares descritos acima (na seção 2.2.1.b) também estão conservados em outros primatas (Eichler et al., Human Molec Genet 5:899, 1996; Regnier et al, Human Molec Genet 6:9, 1997; Grewal et al., Gene 227: 79, 1999).
4.3. Pseudogenes processados. Como o DNA humano pode conter aproximadamente quatro vezes mais pseudogenes processados do que pseudogenes duplicados clássicos (extrapolando dados do cromossomo 22 [Dunham et al, Nature 402:489, 1999]), existem muitos mais exemplos de pseudogenes processados (do que pseudogenes clássicos) compartilhados entre espécies. Descreverei um que meus colegas e eu descobrimos: um pseudogene derivado do gene que codifica a imunoglobulina epsilon – um tipo de anticorpo que participa de reações alérgicas. Em nossos estudos destinados a investigar as bases da alergia, descobrimos uma sequência que se assemelhava ao gene da imunoglobulina epsilon, exceto por não possuir intrões, apresentar múltiplas mutações incapacitantes, ter em sua extremidade uma sequência de quase "A"s contínuos (parecendo um trato de poli(A) levemente mutado) e estar localizado em um cromossomo diferente (cromossomo 9) daquele do gene funcional (cromossomo 14) (Max et al. Cell 29:691, 1982; Battey et al. PNAS 79:5956, 1982). Nossa evidência sugeriu que esse pseudogene processado também existia no DNA de chimpanzés, e investigações detalhadas subsequentes de outros laboratórios (Kawamura e Ueda, Genomics 13:194, 1992) demonstraram que pseudogenes quase idênticos existem em chimpanzés, gorilas, orangotangos e macacos do Velho Mundo. Como no caso de todas as inserções de DNA compartilhadas por diferentes espécies (veja outros exemplos abaixo), o argumento de que essas sequências não foram criadas independentemente, mas descendem de uma inserção ancestral comum, é reforçado pela demonstração de que as inserções ocorreram na mesma posição no DNA de cada espécie, ou seja, o DNA que circunda a inserção é muito similar entre as espécies – tão próximo da identidade quanto se poderia esperar dada a ocorrência de mutações que não são selecionadas contra.
4.4. SINEs. Das cerca de um milhão de cópias de sequências Alu no genoma humano, apenas uma pequena fração foi comparada entre humanos e outras espécies de primatas. No entanto, em vários segmentos longos de DNA onde as sequências correspondentes foram obtidas no DNA humano e de chimpanzé, quase todas as sequências Alu são compartilhadas entre essas duas espécies. Por exemplo, no cluster de genes de globina ![]() mencionado acima, todas as sete sequências Alu encontradas no DNA humano estão presentes no chimpanzé, inseridas exatamente nas mesmas posições (Sawada et al. J Mol Evol 22:316, 1985). O mesmo vale para as sete sequências Alu próximas a um pseudogene derivado do gene de cópia única cdc27hs (Gonzalez et al., Genomics 18:29, 1993).
mencionado acima, todas as sete sequências Alu encontradas no DNA humano estão presentes no chimpanzé, inseridas exatamente nas mesmas posições (Sawada et al. J Mol Evol 22:316, 1985). O mesmo vale para as sete sequências Alu próximas a um pseudogene derivado do gene de cópia única cdc27hs (Gonzalez et al., Genomics 18:29, 1993).
As sequências de muitos repetidores Alu no DNA humano têm sido comparadas, permitindo a classificação em várias famílias, com base no grau de similaridade da sequência. Membros de certas famílias são encontrados no DNA de muitos primatas diversos, enquanto outras famílias parecem ter sido dispersas mais recentemente, pois não são compartilhadas por outras espécies. Vários exemplos de inserções da família "mais recente" são conhecidos por serem polimórficos na população humana: ou seja, ocorrem em alguns indivíduos, mas não em outros. De fato, a frequência de certas inserções Alu em diferentes populações humanas tem sido usada para deduzir prováveis padrões de migração e mistura gênica em nossos ancestrais humanos. Tais observações são consistentes com a inserção de tais cópias Alu após a evolução humana. Além disso, a excelente saúde de indivíduos que carecem de certas inserções Alu apoia a visão de que essas inserções não desempenham nenhuma função importante na fisiologia humana.
4.5. LINEs. Diversas sequências LINE foram encontradas na mesma posição no DNA de humanos e outras espécies, incluindo exemplos no locus da globina, genes de pigmentos visuais e fosfatase alcalina intestinal (revisado por Smit et al. J Mol Biol 246:401,1995). Alguns dos exemplos relatados são compartilhados por espécies tão distintas quanto humanos e vacas, indicando inserções em ancestrais mamíferos muito antigos.
4.6. Retrovírus endógenos. Como os retrovírus endógenos são menos numerosos do que as outras sequências de DNA não funcionais discutidas aqui, e como uma fração relativamente pequena das sequências de DNA humano conhecidas foi comparada entre espécies, há uma escassez de exemplos de retrovírus endógenos compartilhados. No entanto, pelo menos cinco exemplos diferentes de sequências retrovirais quase idênticas incorporadas na mesma posição no DNA humano e de chimpanzé foram relatados (Bonner et al. PNAS 79:4709, 1982; Dangel et al. Immunogenetics 42:41, 1995; Svensson et al Immunogenetics 41:74,1995; Medstrand & Mager J Virol 72:9782, 1998; Barbulescu et al. Curr Biol 9:861, 1999), todos aparentemente exemplos de retrovírus que foram "capturados" pelos ancestrais de nós há milhões de anos. Pode-se antecipar que exemplos adicionais serão descobertos à medida que mais dados de sequenciamento se tornarem disponíveis, especialmente do cromossomo Y, que foi descrito como um "cemitério" para sequências de retrovírus endógenos tanto para humanos quanto para chimpanzés (Kjellman et al. Gene 161:163, 1995).
4.7 Implicações de sequências sem função compartilhadas entre espécies
Todos os exemplos de sequências sem função compartilhadas entre humanos e chimpanzés reforçam o argumento a favor da evolução que seria convincente mesmo se apenas um exemplo fosse conhecido. Este argumento pode ser compreendido por analogia com os casos jurídicos discutidos anteriormente, nos quais erros compartilhados foram reconhecidos como prova de cópia. A aparência do mesmo "erro"—ou seja, o mesmo pseudogene inútil ou sequência Alu ou retrovírus endógeno na mesma posição no DNA humano e de primatas—não pode ser explicado logicamente por origens independentes das duas sequências. O argumento criacionista discutido anteriormente—de que semelhanças na sequência de DNA simplesmente refletem os planos do criador para funções proteicas semelhantes em espécies semelhantes—não se aplica a sequências que não têm qualquer função para o organismo que as abriga. A possibilidade de acidentes genéticos idênticos criarem o mesmo pseudogene ou Alu ou retrovírus endógeno independentemente em duas espécies diferentes por acaso é tão improvável que pode ser descartada. Como nos casos de direitos autorais discutidos anteriormente, tais "erros" compartilhados indicam que alguma forma de cópia deve ter ocorrido. Como não há mecanismo conhecido pelo qual sequências de primatas modernos possam ser copiadas para a mesma posição no DNA humano ou vice-versa, a existência de pseudogenes compartilhados ou retroposons leva à conclusão lógica de que tanto as sequências humanas quanto as de primatas foram copiadas de sequências ancestrais que devem ter surgido em um ancestral comum de humanos e primatas.
Esta evidência de um ancestral comum sela o argumento para a evolução humana/cérebro que decorre de sequências compartilhadas sem função. Embora os exemplos documentados mais numerosos de tais sequências compartilhadas entre espécies diferentes acasalem-se em ligar humanos e primatas (veja, por exemplo, Hamdi et al, J Mol Biol 284:861, 1999), isso simplesmente reflete o fato de que o DNA humano tem sido estudado mais intensivamente do que o DNA de qualquer outra espécie superior, enquanto considerável sequência homóloga de chimpanzé também é conhecida. É óbvio, no entanto, que a lógica idêntica poderia ser usada para ligar outras espécies em diferentes ramos da árvore evolutiva, e tais exemplos têm sido relatados, por exemplo, SINEs esclarecendo relações entre espécies de roedores (Furano J Biol Chem. 270: 25301, 1995; Verneau et al, PNAS 95: 11284, 1998) ou ligando cavalos a rinocerontes (Gallagher et al, Mamm Genome:140, 1999) ou estabelecendo as afinidades filogenéticas de tarsídeos (Schmitz et al., Genetics 157:777, 2001) ou ruminantes pecorinos (Nijman et al J Mol evol 54:9, 2002). Espécies tão distintas quanto humanos e ratos têm sido ligadas por exemplos da antiga família de SINE conhecida como MIRs (Repetições Intercaladas Mamíferas; veja Smit e Riggs, Nucleic Acids Research 23:98, 1995; Jurka et al, Nucleic Acids Research 23:170, 1995) que foram encontradas embutidas na localização homóloga nos genes de mioglobina e N-myc humanos e murinos (Donehower, Nucleic Acids Research 17:699, 1989; note que no momento desta descrição a sequência conservada não era reconhecida como um SINE). Adicionalmente, inserções antigas de LINE ligam humanos a vacas, como mencionado acima (inserções LINE semelhantes localizadas a montante dos genes de fosfatase alcalina intestinal em ambas as espécies), bem como a ratos (inserções LINE semelhantes no primeiro intrão da subunidade alfa2 dos genes de ATPase sódio-potássio; Smit et al, J Mol Biol 246:401, 1995) e a ratos (por exemplo, inserções LINE na região mnd2 do cromossomo 2p13 [Jang et al, Genome Res 9:51, 1998] e próximo ao gene CD4 no cromossomo 12p13 humano [Ansari-Lari et al Genome Res 8:29, 1998]). Com comparações adicionais de sequências de longos trechos homólogos de DNA humano e de rato antecipadas pelo Projeto Genoma Humano e Projeto Genoma do Rato, sequências LINE adicionais compartilhadas entre essas espécies provavelmente serão descobertas.
Um exemplo particularmente impressionante de retroposons compartilhados foi recentemente relatado, ligando cetáceos (baleias, golfinhos e peixes-boi) a ruminantes e hipopótamos, e é instrutivo considerar este exemplo em algum detalhe. Cetáceos são animais que vivem no mar e apresentam semelhanças importantes com mamíferos terrestres; em particular, as fêmeas possuem glândulas mamárias e amamentam seus filhotes. Cientistas que estudam a anatomia e fisiologia dos mamíferos demonstraram as maiores semelhanças entre os cetáceos e o grupo de mamíferos conhecido como artiodáctilos (ungulados de casco par) incluindo vacas, ovelhas, camelos e porcos. Essas observações levaram à visão evolucionista de que as baleias evoluíram de um ancestral artiodátil de quatro patas que vivia na terra. Criacionistas têm aproveitado as óbvias diferenças entre os artiodáctilos familiares e as baleias, e ridicularizado a ideia de que as baleias poderiam ter tido ancestrais terrestres de quatro patas. Criacionistas que afirmam que os cetáceos não surgiram de mamíferos terrestres de quatro patas devem ignorar ou de alguma forma descartar as evidências fósseis de aparentes ancestrais de baleias que parecem exatamente como se poderia prever para espécies transicionais entre mamíferos terrestres e baleias – com pernas diminutas e com estruturas de orelha intermediárias entre as dos artiodáctilos modernos e dos cetáceos (Nature 368:844,1994; Science 263: 210, 1994). (Uma discussão sobre espécies fósseis ancestrais de baleias com referências pode ser encontrada em http://www.talkorigins.org/faqs/faq-transitional/part2b.html#ceta) Os criacionistas também devem ignorar ou descartar as evidências mostrando a grande semelhança entre as sequências gênicas de cetáceos e artiodáctilos (Molecular Biology & Evolution 11:357, 1994; ibid 13: 954, 1996; Gatesy et al, Systematic Biology 48:6, 1999).
Recentemente, evidências de retroposões consolidaram a relação evolutiva entre baleias e artiodáctilos. Shimamura et al. (Nature 388:666, 1997; Mol Biol Evol 16: 1046, 1999; veja também Lum et al., Mol Biol Evol 17:1417, 2000; Nikaido e Okada, Mamm Genome 11:1123, 2000) estudaram sequências SINE altamente reduplicadas no DNA de todas as espécies de cetáceos examinadas. Essas SINES também foram encontradas presentes no DNA de ruminantes (incluindo vacas e ovelhas), mas não no DNA de camelos, porcos ou mamíferos mais distantes, como cavalo, elefante, gato, humano ou canguru. Essas SINES aparentemente originaram-se em um ramo específico de artiodáctilos ancestrais após este ramo divergir de camelos, porcos e outros mamíferos, mas antes da divergência das linhagens que levam aos cetáceos modernos, hipopótamos e ruminantes. (Veja a Figura 5.) Em apoio a este cenário, Shimamura et al. identificaram duas inserções específicas dessas SINES no DNA de baleias (inserções B e C na Figura 5) e demonstraram que no DNA de hipopótamo, vaca e ovelha, esses mesmos dois sítios continham as SINES; mas no DNA de camelo e porco, os mesmos sítios estavam "vazios" de inserções. Mais recentemente, o hipopótamo foi identificado como o parente terrestre vivo mais próximo dos cetáceos, já que hipopótamos e baleias compartilham inserções de retroposões (ilustradas por D e E na Figura 5) que não são encontradas em nenhum outro artiodáctilo (Nikaido et al, PNAS 96:10261, 1999). A estreita relação entre hipopótamo e baleia é consistente com comparações de similaridade de sequências previamente relatadas (Gatesy, Mol Biol Evol 14:537, 1997) e com recentes achados fósseis (Gingerich et al., Science 293:2239, 2001; Thewissen et al., Nature 413:277, 2001) que resolvem conflitos paleontológicos anteriores com a estreita relação entre baleias e hipopótamos. (Alguns leitores têm se perguntado: se os ruminantes estão mais relacionados às baleias do que aos porcos e camelos, por que os ruminantes são anatômicamente mais semelhantes a porcos e camelos do que às baleias? Aparentemente, isso resulta do fato de que ruminantes, porcos e camelos mudaram relativamente pouco desde seu último ancestral comum, enquanto a linhagem dos cetáceos mudou dramaticamente ao se adaptar a um estilo de vida aquático, eliminando assim muitas das características – como cascos, pelos e patas traseiras – que são compartilhadas entre seus parentes ruminantes próximos e os porcos e camelos mais distantes. Este cenário ilustra o fato de que o desenvolvimento evolutivo rápido de adaptações a um novo nicho pode ocorrer através de mutações funcionais-chave, deixando a maior parte do DNA relativamente inalterada. A particularmente estreita relação entre baleias e hipopótamos é consistente com várias adaptações compartilhadas à vida aquática, incluindo o uso de vocalizações subaquáticas para comunicação e a ausência de pelos e glândulas sebáceas.) Assim, as evidências de retroposões suportam fortemente a derivação das baleias de um ancestral comum de hipopótamos e ruminantes, consistente com a interpretação evolutiva dos fósseis e das similaridades gerais de sequências de DNA. De fato, a lógica das evidências de SINES compartilhados é tão poderosa que os SINES podem ser os melhores caracteres disponíveis para deduzir a parentesco entre espécies (Shedlock e Okada, Bioessays 22:148, 2000), mesmo que não sejam perfeitos (Myamoto, Curr. Biology 9:R816, 1999).
|
|
|
Figura 5. Inserções específicas de SINE podem atuar como "rastreadores" que iluminam as relações filogenéticas. Esta figura resume alguns dos dados sobre SINEs encontrados em artiodáctilos vivos e mostra como as inserções compartilhadas podem ser interpretadas em relação ao ramificação evolutiva. Um evento específico de inserção de SINE ("A" na Figura) parece ter ocorrido em um ancestral comum primitivo de porcos, ruminantes, hipopótamos e cetáceos, já que esta inserção está presente nestes descendentes modernos desse ancestral comum; mas está ausente em camelos, que se separaram das outras espécies antes desta inserção de SINE. Inserções mais recentes B e C estão presentes apenas em ruminantes, hipopótamos e cetáceos. As inserções D e E são compartilhadas apenas por hipopótamos e cetáceos, identificando assim o hipopótamo como o parente vivo mais próximo dos cetáceos (pelo menos entre as espécies examinadas nestes estudos). As inserções de SINE F e G ocorreram na linhagem de ruminantes após ela se divergir das outras espécies; e as inserções H e I ocorreram após a divergência da linhagem dos cetáceos. |

Embora alguns criacionistas aceitem as evidências para a seleção natural de variantes menores (por exemplo, a divergência das finchas de Darwin nas ilhas Galápagos), que eles chamam de "microevolução", a maioria dos criacionistas nega que a evolução possa explicar mudanças mais significativas, que eles designam como "macroevolução". No entanto, os pseudogenes/retrotransposons compartilhados descritos aqui fornecem fortes evidências de que os humanos compartilham ancestrais comuns com espécies tão distintas quanto macacos, vacas e ratos. Assim, mesmo que possamos carecer de evidências convincentes de que qualquer fóssil específico seja ancestral para uma espécie moderna particular, e mesmo que não tenhamos evidências fósseis que identifiquem claramente o último ancestral comum entre humanos e vacas ou entre baleias e ruminantes, podemos ter confiança, a partir dos erros compartilhados descritos aqui, de que essas espécies ancestrais comuns existiram. Esta conclusão, por sua vez, implica que características novas significativas (por exemplo, a marcha bípede humana e o desenvolvimento cerebral, e as adaptações dos cetáceos à vida aquática) devem ter surgido entre o tempo em que os respectivos ancestrais comuns viveram e os dias de hoje. Essas mudanças são claramente extensas o suficiente para serem chamadas de "macroevolução", de modo que o "argumento dos erros compartilhados" é uma evidência poderosa para a macroevolução. Esta conclusão parece sólida, já que nenhuma explicação alternativa para esses erros compartilhados, consistente com a origem independente dessas espécies animais, foi proposta na literatura científica.
Claramente, o argumento dos "erros compartilhados" fornece fortes evidências para mudanças macroevolutivas na evolução dos mamíferos e, portanto, refuta uma posição criacionista amplamente aceita. Mas, para ser justo, devemos deixar claro que este argumento não compra todo o jogo evolucionista. Embora as evidências de erros compartilhados impliquem a descendência comum de diversas espécies de mamíferos, não abordam se essas espécies evoluíram de seus últimos ancestrais comuns através dos mecanismos darwinianos de mutação e seleção natural ou através de outros mecanismos alternativos. Outra limitação é que não há exemplos de "erros compartilhados" que liguem mamíferos a outras ramificações da árvore genealógica da vida na Terra. Por exemplo, embora espécies tão diversas quanto vermes, leveduras e plantas tenham elementos LINE em seus genomas, não foram relatados, ao meu conhecimento, exemplos de inserções específicas de LINE em posições homólogas entre qualquer mamífero e não-mamífero (embora eu bem-vinda contribuições dos leitores sobre este ponto). Tais exemplos poderiam ser esperados para ser difíceis de encontrar, uma vez que os últimos ancestrais comuns de mamíferos e répteis são pensados para ter vivido há mais de 200 milhões de anos, tempo suficiente para que similaridades de sequência que uma vez existiram em DNA sem função como pseudogenes e retrotransposons tenham sido em grande parte apagadas pela acumulação de numerosas mutações. Portanto, as relações evolutivas entre ramificações distantes na árvore genealógica evolutiva devem repousar em outras evidências além dos "erros compartilhados". (Tais evidências podem incluir outras "mudanças genômicas raras" (RGCs) além da inserção de retrotransposon, como inserção ou deleção de sequências codificantes ou intrões (por exemplo, Venkatesh et al., PNAS 98:11382, 2001), translocações cromossômicas e inversões reveladas por citogenética comparativa, e variantes no código genético, todos resumidos em Rokas e Holland, Trends Ecol & Evol 15:454, 2000. A parentesco entre espécies também pode ser inferido de árvores de similaridade de sequência tradicionais baseadas em comparações dos genes correspondentes de diferentes espécies.) Como uma limitação final e bastante óbvia do argumento dos "erros compartilhados", deve ser claro que este argumento não se refere a questões de origem da vida, que criacionistas comumente agrupam com a evolução.
5. Respostas dos criacionistas ao argumento das sequências compartilhadas sem função
Criacionistas tendem a evitar mencionar o argumento apresentado neste ensaio, pois ele fornece evidências persuasivas para a evolução, mas o porta-voz criacionista Duane Gish comentou sobre o argumento quando foi confrontado com ele em debates; e algumas outras discussões criacionistas sobre pseudogenes já apareceram. Vamos primeiro examinar algumas das respostas do Dr. Gish.
5.1 Alguns "pseudogenes" processados são funcionais, portanto, poderiam ser exemplos de "design similar para função similar."
Como mencionado acima (2.2.1.c), cópias retrotranscritas de transcritos de RNA de genes podem, raramente, inserir-se no DNA próximo a um promotor existente ou de outra forma que permita sua transcrição de maneira útil para o organismo. Tais cópias (que são realmente genes processados e não pseudogenes processados) podem, portanto, fornecer alguma função que exerce pressão seletiva contra mutações deletérias. Vários exemplos dessa possibilidade foram relatados, conforme mencionado acima na seção 2.2.1.c; e estes poderiam ser interpretados como "design similar para função similar". Mas esses exemplos compartilham uma característica que claramente os distingue dos centenas de exemplos de pseudogenes processados inúteis relatados: eles carecem de mutações deletérias que impediriam a função e, assim, permanecem capazes de codificar uma proteína útil. Entre pseudogenes processados de verdade — ou seja, cópias de genes retropostas com múltiplas mutações deletérias, como códon de parada —, não foram relatados exemplos com função documentada [Veja nota adicionada abaixo]. (Leitores que acreditam que existem exemplos contradizendo esta declaração são convidados a entrar em contato comigo com as referências bibliográficas; modificarei este artigo conforme necessário.) Assim, o argumento do Dr. Gish simplesmente reflete sua errônea agrupação de duas classes distintas de cópias de genes retropostas: genes processados e pseudogenes processados. E o Dr. Gish ainda não ofereceu nenhum argumento que explicaria — em termos de função projetada inteligentemente — os numerosos exemplos de sequências retropostas compartilhadas que, ao contrário dos pseudogenes, nem sequer derivam de DNA que tem um papel funcional.
Nota adicionada em 5 de maio de 2003: Um exemplo de pseudogene com função documentada foi recentemente relatado. Uma sequência chamada Makorin1-p1 não codifica uma proteína funcional, mas seu transcrito de mRNA estabiliza o mRNA do gene funcional Makorin1 do qual aparentemente foi derivado (Hirotsune et al, Nature 423:91,2003). O conhecimento atualmente disponível da literatura publicada não sugere papéis funcionais para pseudogenes processados além do Makorin1-p1. É possível que estudos futuros descubram outros pseudogenes com aparente função (mas veja a próxima seção).
5.2 Alguns órgãos anteriormente considerados vestigiais foram mais recentemente encontrados ter função; sabemos muito pouco sobre essas novas características de DNA descobertas para ter confiança de que a função não será descoberta para elas no futuro.
Imagine um réu em um julgamento por homicídio defendendo-se contra provas incriminadoras esmagadoras com o argumento paralelo: que, como alguns criminosos condenados foram posteriormente absolvidos, ele (o réu atual) deveria, portanto, ser absolvido agora, porque, em algum momento no futuro, pode-se encontrar evidências para absolvê-lo! Essa defesa seria tão ridícula quanto o argumento do Dr. Gish. Cientistas (e júris) devem basear suas conclusões nas melhores evidências disponíveis no momento. É verdade que evidências posteriores podem absolver um criminoso condenado ou derrubar uma teoria científica. Essa possibilidade deve fomentar humildade e nos alertar contra conclusões dogmáticas (e talvez contra a pena de morte); mas não deve nos dissuadir de tirar as conclusões mais razoáveis dos dados em mãos. Nosso conhecimento atual suporta a interpretação de que a maioria dos pseudogenes/retroposons compartilhados são evidências de descendência comum e macroevolução. Se no futuro—for uma sequência particular de Alu ou LINE-1 ou retrovírus endógeno compartilhada entre humanos e outra espécie—forem descobertas evidências de função, então essa sequência particular poderia, de fato, ser razoavelmente interpretada pelo paradigma criacionista de "sequência similar projetada para função similar"; e, portanto, esse retroposon teria que ser removido da lista de sequências sem função compartilhadas que fornecem evidências para a evolução. As centenas de milhares de exemplos restantes nesta lista continuariam a oferecer suporte válido para a evolução.
Além disso, embora essas sequências de DNA vestigiais tenham sido descobertas mais recentemente do que os órgãos vestigiais conhecidos na época de Darwin, sabemos o suficiente sobre como elas surgem para não precisarmos postular nenhum designer misterioso ou função desconhecida para explicá-las. Sabemos que os pré-requisitos para a formação de SINEs e outros retroposons — ou seja, transcritos de RNA e transcriptase reversa — estão presentes em baixos níveis em células germinativas estudadas em laboratório, onde seriam capazes, sem qualquer intervenção sobrenatural, de gerar retroposons que poderiam ser transmitidos às gerações futuras. Este fato prevê que as inserções de retroposons devem estar ocorrendo em alguma frequência até mesmo hoje. De fato, inserções específicas de sequências Alu no DNA de indivíduos vivos já foram documentadas. Por exemplo, um elemento Alu foi encontrado inserido no DNA de um paciente com neurofibromatose tipo I, danificando o gene associado a essa doença (Wallace et al. Nature 353:6347, 1991). O pai e a mãe do paciente possuíam cópias intactas do gene sem inserção Alu, portanto a inserção deve ter ocorrido nas células germinativas de um dos pais ou muito cedo no desenvolvimento embrionário do paciente. Da mesma forma, um elemento LINE recém-inserido foi encontrado danificando o gene para uma proteína de coagulação sanguínea, causando hemofilia em outro paciente cujos pais não possuíam essa inserção (Kazazian et al. Nature 332:164, 1988). (Outros exemplos de inserção de LINE ou Alu causando doenças são revisados por Kazazian [in Curr Opin Genet & Devel 8:343, 1998], por Miki [Human Genetics 43:77, 1998] e por Deininger e Batzer [Molec Genet & Metab 6:183, 1999].) Novos eventos de retroposição são estimados em ocorrer em 1% a 10% da população humana (Kazazian Nature Genet 22:130, 1999). Carlton et al (Mamm Genome 6:90, 1995) observaram o aparecimento de novo de um pseudogene processado quando forneceram uma fonte de transcriptase reversa infectando células cultivadas com um retrovírus; enquanto Esnault et al. (Nature Genet 24:363, 2000) e Wei et al. (Molec Cell Biol 21:1439, 2001) observaram a formação de pseudogenes processados resultante da RT de um elemento LINE humano. Usando um ensaio sensível para detectar retroposição, Maestre et al. (EMBO J 14:6388, 1995) foram capazes de detectar cópias retropostas de uma sequência de gene marcada sendo inseridas no DNA de células humanas enquanto elas cresciam em laboratório, mesmo sem a adição de transcriptase reversa exógena. Além disso, Jensen e Heidmann (EMBO J 10:1927, 1991) detectaram a retroposição contínua de uma cópia marcada de LINE em Drosophila.
Recentemente, Feng et al. (Cell 87: 905, 1996) demonstraram que a enzima transcriptase reversa ativa codificada por uma cópia recém-inserida de LINE possui uma atividade adicional inesperada: é uma endonuclease, ou seja, é capaz de causar cortes em DNA que poderiam servir como pontos de inserção para novos eventos de retroposição. Na verdade, essa endonuclease corta o DNA com características de sequência específicas, e as mesmas características foram observadas nas posições de inserção de várias cópias de LINE selecionadas aleatoriamente do DNA humano. (Veja também Cost e Boeke, Biochemistry 37:18081, 1998). Este resultado sugere que as sequências de LINE estão tão bem adaptadas para a replicação "egoísta" no genoma que não dependem de quebras aleatoriamente geradas no DNA para suas inserções, mas geram seus próprios cortes. Para testar essa ideia, Moran et al. (Cell 87:917, 1996; veja também Ostertag et al., Nucl Ac Res 28:1418, 2000) construíram uma sequência de LINE projetada de modo que, se ela gerasse quaisquer novas cópias retropostas em qualquer célula, essas células pudessem ser selecionadas e contadas. Quando essa sequência foi inserida em células de cultura de tecido humano, novas cópias retropostas foram rotineiramente produzidas. Ao testar os efeitos de mutações em vários segmentos da sequência de LINE, demonstrou-se que a retroposição eficiente exigia tanto a atividade de transcriptase reversa quanto a atividade de endonuclease presentes na mesma proteína. (Esta proteína também é necessária para a formação eficiente de pseudogenes processados induzidos por LINE [Esnault et al. Nature Genet 24:363, 2000]).
Observações como estas reforçam a noção de que as sequências de retroposão que observamos no nosso DNA e no DNA de outros mamíferos não foram criadas por forças misteriosas que atuaram apenas no passado distante para propósitos inescrutáveis, mas por acidentes genéticos simples que ocorrem com baixa frequência como resultado de peculiaridades da bioquímica celular e que não servem a nenhum propósito. O fato de que uma pequena fração destes acidentes genéticos possa criar alguma função benéfica (Britten RJ PNAS 93:9374,1996; Britten RJ Gene 205:177,1997) não enfraquece em nada esta interpretação; tais eventos são simplesmente exemplos de mutações benéficas raras cuja ocorrência forma a base para a mudança evolutiva adaptativa e cuja existência parece tão difícil para os criacionistas de aceitar. Como é o caso para a maioria das mutações, a esmagadora maioria das inserções de retroposão ocorre no DNA não funcional entre genes e não tem efeito sobre a célula ou o organismo; e é este vasto conjunto de inserções, compartilhado entre espécies, que fornece a base para o presente argumento a favor da evolução.
5.3 Se todas essas sequências fossem realmente não funcionais, teriam sido eliminadas ao longo do tempo evolutivo.
Este argumento reflete ignorância dos fatos discutidos acima na seção 3. Para repetir: não se conhece nenhum mecanismo pelo qual sequências de DNA não funcionais possam ser distinguidas das funcionais e alvo de eliminação por enzimas celulares. Bactérias parecem estar sob pressão seletiva para eliminar DNA não funcional; cromossomos bacterianos têm muito pouco DNA entre genes, talvez porque a competição sob condições de crescimento rápido possa favorecer cromossomos que se replicam rapidamente — ou seja, os mais curtos — e, portanto, podem selecionar células que tenham deletado qualquer DNA não funcional. Mas não há evidências para tal pressão seletiva em cromossomos mamíferos, nos quais os genes estão amplamente separados uns dos outros e nas quais as regiões não funcionais aparentemente constituem 90-95% do DNA. De fato, poderia-se perguntar: por que então nossos cromossomos não estão repletos de sequências de retroposon a uma frequência ainda maior do que a realmente observada? Uma resposta razoável é que nossos ancestrais estavam sob pressão seletiva para suprimir a retroposição, já que altas frequências de inserção de retroposon aumentariam a taxa de dano genético causado por inserções incapacitantes em genes. Além disso, é concebível que uma fração maior do nosso DNA tenha originado através de retroposição do que podemos agora reconhecer; alguns pseudogenes ou inserções de retroposon muito antigos podem ter sofrido tantas mutações aleatórias desde sua inserção que suas identidades como pseudogenes ou retroposons foram apagadas. No entanto, à taxa de mutação estimada para sequências não selecionadas, a completa aniquilação de um retroposon típico por mutações exigiria mais de 100 milhões de anos. Portanto, não seria surpreendente para um evolucionista que sequências de retroposon sem função que se inseriram em um ancestral comum de humanos e vacas ainda possam ser detectáveis por comparações computadorizadas de sequências de DNA.
5.4 Foram descobertos papéis importantes para regiões de DNA anteriormente consideradas sem função
Em um debate recente comigo, o Dr. Gish citou uma revisão na Science intitulada "Mining treasures from 'junk' DNA" (263:608, 1994), parecendo implicar que esta revisão sugere funções para pseudogenes e retrotransposons que seriam consistentes com a visão criacionista de que foram projetados para funcionar de maneira similar em espécies similares. Na verdade, esta revisão discute evidências para possíveis funções de sequências repetitivas centroméricas e teloméricas, minissatélites, intrões e regiões não traduzidas 3'. Ela menciona pseudogenes e retrotransposons, mas não faz nenhuma sugestão de que esses elementos particulares tenham função, portanto esta revisão não oferece nenhum argumento contra os pontos feitos neste ensaio. No entanto, já que houve outras especulações sobre possíveis funções para DNA fora de sequências de codificação gênica, vale a pena considerar por que os cientistas geralmente aceitam a noção de que a maior parte deste DNA é lixo.
Primeiro, sabemos de vários mecanismos pelos quais o comprimento do DNA pode ser aumentado por acidentes genéticos, como duplicações de DNA e inserção de retrotransposons, que foram observados em laboratório ou ocorrem em humanos sem efeitos aparentes; portanto, é razoável supor que esses mecanismos operaram no passado para aumentar o tamanho do genoma sem afetar a função. Parece haver pouca ou nenhuma pressão seletiva para reduzir o tamanho dos genomas nucleares de vertebrados; e não há mecanismo aparente para eliminar seletivamente o DNA inútil. Grandes deleções que eliminam DNA funcional são selecionadas contra. Essas observações preveriam o acúmulo de DNA inútil como resultado de acidentes genéticos aleatórios, de modo que, quando vemos DNA que parece não funcional, não devemos necessariamente assumir que ele tem uma função que não entendemos.
Segundo, quando a sequência de DNA é comparada entre espécies, como humano versus rato, sequências que se sabe que têm função — em particular, sequências codificantes de genes — são encontradas altamente similares, consistente com a pressão seletiva que elimina indivíduos que possuem mutações deletérias nessas regiões funcionais. Por outro lado, regiões de DNA sem função conhecida — por exemplo, sequências não codificantes entre genes — geralmente comportam-se como se não estivessem sob pressão seletiva, ou seja, aparentemente acumulam mutações a uma taxa muito mais elevada, de modo que há pouca conservação de sequência entre espécies distantly relacionadas. Como uma exceção que testa a regra, comparações de sequência não codificante entre espécies ocasionalmente detetam "ilhas" de sequência conservada curta em regiões não codificantes. Algumas destas revelaram-se corresponder a regiões reguladoras, como elementos promotor ou potenciador, que controlam quando um gene próximo é expresso. Um exemplo de tal "ilha" conservada entre coelho, rato e humano foi descoberto no meu próprio laboratório [Emorine et al., Nature 304:447, 1983]; revelou-se representar um potenciador importante. Estes tipos de regiões reguladoras ocupam geralmente muito menos DNA do que as sequências codificantes dos genes que regulam, por isso não podem representar uma função provável para a maioria do DNA não codificante. A boa correlação entre função e conservação de sequência apoia a ideia de que a maioria das sequências pouco conservadas não tem função. No entanto, deve notar-se que para a maioria das "ilhas" de sequência conservada em DNA entre genes (Shabalina et al., Trends Genet 17:373, 2001), ainda não foi descoberta nenhuma função. Algumas podem incluir espécies de RNA que funcionam sem serem traduzidas em proteína.
Um terceiro, mas relacionado, argumento deriva da observação de que a inserção de um retroposon em uma sequência funcional é uma maneira potente de destruir essa função. Exemplos de inserções naturalmente ocorrentes foram discutidos na seção 5.2 acima; e a inserção intencional de retroposons está sendo amplamente utilizada como ferramenta de laboratório para criar painéis de linhagens de camundongo, drosophila ou levedura com diferentes funções gênicas destruídas. No entanto, a maioria dos exemplos de inserções de retroposons entre genes não tem qualquer aparente efeito sobre os indivíduos que as abrigam; por exemplo, as sequências Alu que são polimórficas no DNA humano parecem ser inofensivas quando presentes. Portanto, é razoável inferir que essas inserções não interromperam nenhuma sequência funcional. (É claro que é impossível excluir a possibilidade formal de que algumas sequências funcionais hipotéticas fora dos genes ainda possam funcionar apesar da presença de uma inserção de retroposon.)
Finalmente, são conhecidos vários exemplos de pares de espécies que possuem complexidade aparente semelhante, mas tamanhos de genoma muito diferentes (paradoxo do valor C). O peixe-porco-dourado Fugu tem cerca de um quarto do tamanho do genoma de outras espécies de peixes, mas aproximadamente o mesmo número de genes. A principal diferença é uma menor quantidade de DNA entre os genes no DNA do Fugu (por exemplo, veja Elgar et al. Genome Res 9:960, 1999). Embora permaneçam questões sobre a interpretação dessa diferença, parece que grande parte do DNA entre os genes na maioria dos genomas de peixes (e provavelmente no nosso também) é dispensável. (Por outro lado, as pequenas regiões de sequência não codificante que são conservadas entre Fugu e Homo frequentemente correspondem a sequências regulatórias funcionais.)
É impossível provar a ausência de função para qualquer região de DNA. Além disso, é provável que alguma função possa ser encontrada para algumas regiões curtas adicionais de DNA não codificante que atualmente não são reconhecidas como tendo função. No entanto, como indicado acima, os cientistas tiram conclusões provisórias com base nos dados atualmente disponíveis, e não em possibilidades hipotéticas de dados futuros; e os argumentos que acabei de apresentar, baseados nas evidências atualmente disponíveis, sugerem que a maioria das sequências de DNA que parecem não ter função é realmente assim.
5.5 Os pseudogenes têm uma função: fornecem uma cópia de "backup" que pode ser corrigida para codificar uma proteína útil caso o gene funcional sofra uma mutação crítica.
O Dr. Gish não forneceu especificações para esta alegação, mas talvez ele estivesse se referindo a uma sugestão recente de que um pseudogene de ribonuclease seminal bovina foi recentemente "corrigido" para se tornar funcional por um processo conhecido como "conversão gênica" (Trabesinger-Ruef et al. FEBS Lett 382:319, 1996). Embora isso possa ocasionalmente acontecer, muito mais instâncias foram descritas na literatura em que defeitos em um pseudogene induzem mutações prejudiciais em um gene funcional próximo por conversão gênica, inativando o gene funcional. Como exemplo deste tipo de evento, em quase todos os pacientes que sofrem de deficiência em steroid 21-hidroxilase porque sua cópia do gene 21-hidroxilase "B" (normalmente) funcional foi inativada por mutações pontuais, essas mutações aparentemente resultaram de conversão gênica pela cópia do pseudogene "A" (Collier et al, Nat Genet 3:260, 1993; Carrera et al. Hum Hered 43:190, 1996). Conversões gênicas similares por um pseudogene são consideradas ter inativado o gene glucocerebrosidase em pacientes com doença de Gaucher (Eyal et al. Gene 96:277, 1990), o gene 14.1 que codifica uma "cadeia leve substituta" de imunoglobulina em um paciente com imunodeficiência (Minegishi et al., J Exp Med 187:77, 1998), o gene ABCC6 em pacientes com pseudoxantoma elástico (Cai et al, (J Mol Med 79:536,2001), o gene PKD1 na doença policística renal autossômica dominante (Watnick et al. Hum Mol Genet 7:1239, 1998), o gene beta-cristalina B2 na catarata hereditária autossômica dominante (Vanita et al. J Med Genet 38:392,2001), o gene NCF1 na doença granulomatosa crônica (Vazquez et al., Exp Hematol 29:234,2001) e o gene do fator von Willebrand em pacientes com doença de von Willebrand (Eikenboom et al., PNAS 91:2221, 1994), para citar apenas alguns exemplos. Em outros casos, eventos de conversão gênica aparentemente transferiram informações genéticas entre dois pseudogenes (Shapiro e Moshirfar, J Mol Biol 209:181, 1989) ou entre dois genes funcionais (Ollo e Rougeon, Cell 32:515, 1983). Como a conversão gênica envolvendo pseudogenes tem sido relatada para ocorrer com efeitos prejudiciais ou neutros mais do que com efeitos benéficos, a hipótese de que pseudogenes foram "projetados" com o potencial de conversão gênica como seu propósito parece pouco convincente. (O único exemplo onde cópias de pseudogenes claramente cumprem uma função importante ao transferir sua sequência para outra cópia de gene por conversão gênica ocorre na diversificação somática de genes da região variável de imunoglobulinas de galinhas e coelhos; das muitas mutações que são geradas por este mecanismo, aquelas poucas que fornecem um "ajuste melhor" entre a imunoglobulina e seu antígeno alvo são selecionadas para expressão. Esta seleção para função melhorada entre genes que sofreram mudanças de sequência quase aleatórias é um modelo biológico atraente para as melhorias evolutivas na função proteica. Ironia das ironias, em vários debates comigo, o Dr. Gish negou que tal diversificação somática ocorre, embora ele claramente estivesse totalmente ignorante sobre a literatura científica concernente a genes de anticorpos.) Além de ser pouco convincente pela razão descrita acima, a ideia do Dr. Gish de que pseudogenes foram criados para fornecer uma cópia de gene de "backup" não oferece nenhuma explicação criacionista para os retroposons compartilhados mais numerosos que não são pseudogenes.
5.6 Tudo isso sobre retrotransposões é realmente muito difícil de entender.
O Dr. Gish usou este apelo ao público em um debate recente comigo. Ele parecia estar tentando convencer o público a ignorar as implicações do argumento dos pseudogenes compartilhados e a desconsiderar o fato de que ele (o Dr. Gish) não conseguia encontrar contra-argumentos válidos para se opor a ele. Esta é uma manobra típica de debate dos criacionistas: usar humor ou invocação da fé ou algum outro apelo irrelevante para distrair um público leigo de perceber que uma posição criacionista foi efetivamente refutada.
(Este ensaio foi enviado ao Dr. Gish para solicitar quaisquer argumentos adicionais contra os pontos aqui apresentados. Nenhuma resposta foi recebida.)
5.7 Além do Dr. Gish, o criacionista John Woodmorappe comentou sobre pseudogenes (Noah's Ark, a Feasibility Study, 1996, publicado pela ICR, p. 202; Bible-Science News 33:7, 1995). Ele apresenta vários dos mesmos argumentos do Dr. Gish (veja 5.2 e 5.4 acima), mas adiciona alguns de sua própria autoria. Uma interpretação criacionista de pseudogenes oferecida por Woodmorappe é que alguns pseudogenes podem ser "o resultado de mudanças degenerativas em organismos vivos desde a Queda". Essa interpretação parece plausível e, se ignorarmos a parte da "Queda", não é muito diferente da ideia evolutiva de que pseudogenes surgem por acidentes genéticos aleatórios. No entanto, essa interpretação ignora completamente o fato de que muitos pseudogenes são compartilhados entre primatas e humanos, localizados nas mesmas posições e compartilhando os mesmos defeitos genéticos, aparentemente o resultado do mesmo acidente genético ou "mudança degenerativa" em um ancestral comum. (Se esses pseudogenes compartilhados surgiram após a "Queda", conforme sugerido por Woodmorappe, a "Queda" talvez tenha ocorrido antes da divergência do homem dos primatas?)
5.8 Ao abordar pseudogenes compartilhados, Woodmorappe tenta obscurecer seu forte apoio à evolução ao alegar que, para pseudogenes específicos, o grau de "parentesco" inferido a partir da presença ou ausência do pseudogene em diferentes espécies contradiz o "parentesco" das espécies inferido por evolucionistas a partir de outras características. Neste argumento, Woodmorappe alinha-se com outros argumentos criacionistas que nos convidam a descartar a evolução devido a casos específicos que violam uma interpretação simplista da evolução, e a ignorar o vasto número maior de exemplos que apoiam a evolução. Na longa e complexa história da vida na Terra, muitas exceções a noções simplistas foram geradas — por exemplo, casos em que fósseis mais antigos estão acima de fósseis mais jovens (devido ao dobramento de camadas geológicas ou falhas de empurrão) ou exemplos em que semelhanças de sequências de pequenos trechos de DNA comparados entre espécies parecem violar relações aceitas (devido a erros estatisticamente esperados devido a amostras pequenas). Da mesma forma, podemos esperar casos em que um pseudogene ou retroposon que surgiu no ancestral de três espécies modernas (A, B e C) possa ser deletado em uma delas (digamos, C), sugerindo uma relação mais próxima entre A e B do que o justificado por outros fundamentos. Um exemplo como este não deve nos levar a descartar o que aprendemos da maioria dos pseudogenes e retroposons compartilhados; pelo contrário, devemos ter cautela ao fazer generalizações a partir de casos excepcionais.
| Caixa 3 |
|---|
|
Woodmorappe descreve um exemplo de pseudogene de imunoglobulina epsilon que foi relatado (Ueda et al, PNAS 82: 3712 1985) como compartilhado por gorila e homem, mas não por chimpanzé, parecendo contradizer a visão evolutiva convencional de que os ancestrais humanos divergiram da linhagem gorila antes de divergirem da linhagem chimpanzé. Infelizmente, Woodmorappe não considerou dados posteriores do laboratório de Ueda (Kawamura e Ueda, Genomics 13:194, 1992) que estavam disponíveis quando Woodmorappe escreveu em 1994 (Bible Science News 32:4 p. 12). Esses dados mais recentes mostram que deleções de DNA que destruíram cópias duplicadas dos genes de imunoglobulina epsilon (1) ocorreram independentemente nas linhagens humana e gorila (a independência foi deduzida do fato de que as fronteiras "direita" e "esquerda" do DNA deletado eram completamente diferentes nas duas espécies), e (2) também ocorreram (novamente independentemente) no chimpanzé. Assim, o exemplo de Woodmorappe de um pseudogene compartilhado que liga humanos a gorilas, mas não a chimpanzés (em aparente violação da divergência mais recente dos ancestrais humanos do chimpanzé aceita pela maioria dos evolucionistas) está incorreto: estes não são pseudogenes "compartilhados", mas pseudogenes que surgiram independentemente, e o chimpanzé possui uma deleção similar, embora maior. (Devo mencionar que citei o mesmo exemplo incorreto na minha versão original deste ensaio. No entanto, na época em que escrevi—1986—o exemplo era apoiado pelas evidências então disponíveis; e publiquei uma correção em Creation/Evolution após os novos dados terem sido publicados. Também devo enfatizar que o exemplo do pseudogene epsilon processado mencionado na seção 4.3 acima representa uma sequência completamente diferente, que ninguém contesta ser compartilhada por humanos, chimpanzés e gorilas.) |
No entanto, o exemplo de pseudogenes compartilhados que Woodmorappe oferece para desafiar o modelo evolutivo tem uma explicação mais mundana: baseia-se simplesmente em informações desatualizadas e incorretas (veja caixa 3).
5.9 Uma hipótese final oferecida pelo Sr. Woodmorappe (em correspondência pessoal) é que genomas semelhantes (como os dos humanos e chimpanzés) podem tender a adquirir os mesmos pseudogenes independentemente, enquanto genomas menos semelhantes podem ser menos capazes de adquirir os mesmos pseudogenes. Esta hipótese ad hoc obviamente explicaria teoricamente por que—even se humanos e chimpanzés foram criados independentemente—eles podem compartilhar mais pseudogenes do que pares de espécies menos semelhantes e independentemente relacionadas, como humanos e gibão. O problema com esta hipótese é que a ocorrência independente—ou seja, em dois indivíduos diferentes—do mesmo retroposon inserindo-se na mesma posição quase nunca foi relatada, mesmo em indivíduos da mesma espécie. Eu consegui encontrar apenas quatro publicações descrevendo exemplos de inserções idênticas independentes. Uma envolve um vírus da sarcoma de Rous modificado, projetado com um marcador selecionável específico, infectando fibroblastos de peru cultivados em cultura de tecidos (Shih et al, Cell 53:531, 1988); e mesmo neste artigo incomum com um vírus especialmente projetado, a frequência de tais inserções foi estimada em apenas 1 em 4000 eventos de inserção. O segundo exemplo é uma publicação muito recente e controversa (Slattery et al., Mol Biol Evol 17:825, 2000) que interpreta duas inserções idênticas de um SINE na mesma localização (um intrão do gene Smcy) em um gato doméstico e um onça-pintada como representando inserções independentes, em vez de refletir uma única inserção em um ancestral felino comum. Duas publicações adicionais (Kass et al, J Mol Evol 51:256 2000; Cantrell et al., Genetics 158:769, 2001) descrevem aparentes inserções idênticas, mas independentes, de SINEs em espécies de camundongo. (John Woodmorappe recusou-se a citar qualquer dado quando desafiado a fornecer exemplos de inserções independentes. No entanto, se os leitores deste ensaio estiverem cientes de outras evidências para inserções independentes do mesmo elemento na mesma posição em qualquer modelo de laboratório, apreciaria citações apropriadas e atualizarei este ensaio para refleti-las.) Muito muitas inserções naturalmente ocorridas foram documentadas em elementos TY de levedura, gypsy e elementos P de drosophila, retrovírus e transgenes murinos, e inserções de HIV humano—todas sem que tenham sido relatadas inserções independentes idênticas. Se organismos independentes da mesma espécie (ou seja, com genomas mais idênticos do que humanos versus chimpanzés) quase nunca adquirem o mesmo pseudogene ou inserção de retroposon na mesma posição, é difícil levar a sério a hipótese de que, por exemplo, as mesmas sete inserções Alu nas mesmas posições do locus globin humano e chimpanzé ![]() (veja a seção 4.4 acima) poderiam ter ocorrido como 14 eventos de inserção independentes.
(veja a seção 4.4 acima) poderiam ter ocorrido como 14 eventos de inserção independentes.
5.10 Não poderia um pseudogene ter sido transmitido por um vírus de uma espécie para outra, levando a pseudogenes compartilhados? Uma proposta ao longo dessas linhas foi sugerida pelo anti-evolucionista Pat Kohli e parece superficialmente plausível. Vários vírus, incluindo retrovírus, são conhecidos por ocasionalmente captarem sequências de nucleotídeos de uma célula "doadora", que podem, após a reinfecção de uma nova célula, serem inseridos no DNA da nova célula "receptora". De fato, este mecanismo é conhecido por ter consequências significativas: se o DNA transmitido inclui uma versão mutada de certos genes chave que regulam a divisão celular, tal sequência de DNA pode atuar como um oncogene e causar malignidade na célula receptora (Bishop, Cell 42:23, 1985). Teoricamente, uma sequência de pseudogene ou retroposon poderia ser capturada por um vírus e então ser transmitida entre espécies por este mecanismo, levando à existência de sequências inúteis idênticas compartilhadas entre duas espécies. De fato, foram relatados casos raros de aparente transferência entre espécies de retroposons (por exemplo, entre duas espécies de moscas-das-frutas [Jordan et al, PNAS 96: 12621, 1999] ou de cobra venenosa para ruminantes [Kordis e Gubensek, PNAS 95:10704, 1998; Kordis, Genetica 107:121, 1999]). No entanto, isso não é provável que seja a explicação para a maioria dos pseudogenes/retroposons compartilhados por pelo menos três razões.
Primeiro, pseudogenes/retroposons compartilhados são geralmente encontrados na posição exatamente homóloga no DNA de cada espécie. Isso é quase sempre verdadeiro no caso de pseudogenes clássicos, que estão em proximidade próxima ao gene funcional, e também é verdadeiro para sequências Alu como as mencionadas no cluster do gene globina, e para pseudogenes processados cuja localização foi determinada (por exemplo, o pseudogene processado de imunoglobulina epsilon humano mencionado acima [Ueda, et al, EMBO J 1:1539, 1982; Tanabe et al. Cytogenet Cell Genet 73:92, 1996]). Os sítios-alvo para inserção viral podem compartilhar certas características de sequência local (Craigie in Trends in Genetics 8:187, 1992; Knoblauch et al., J Virol 70:3788, 1996; Stevens e Griffith, PNAS 91:5557, 1994), mas essas características ocorrem com bastante frequência e estão geralmente espalhadas pelo DNA da célula receptora. Além dos artigos mencionados na seção 5.9, não há precedente ou mecanismo conhecido para um segmento de DNA transmitido viralmente alvejar uma localização específica no DNA da célula receptora, como seria necessário para que um pseudogene representando uma inserção viral hipotética ocorresse na mesma localização da sequência doadora hipotética. Portanto, as localizações compartilhadas de pseudogenes/retroposons em relação ao DNA circundante argumentam fortemente contra tal modelo de transmissão entre espécies.
Em segundo lugar, se a maioria dos pseudogenes/retroposons compartilhados representasse transferência mediada por vírus de uma espécie para outra, esperaria-se encontrar sequências virais próximas aos pseudogenes em espécies "receptoras". Tais sequências virais estão regularmente presentes em exemplos conhecidos de transmissão de DNA de uma célula para outra, incluindo inserções de construções retrovirais projetadas; no entanto, sequências virais não são encontradas associadas à maioria dos pseudogenes/retroposons, exceto os retrovírus endógenos.
Finalmente, várias árvores genealógicas foram geradas comparando, entre espécies, a presença ou ausência de inserções LINE ou Alu em locais específicos do genoma, um exercício semelhante ao mostrado na Figura 5 acima (Malik et al, Mol Biol Evol 16: 793, 1999; Hamdi et al J Mol Biol 284:861, 1999); as árvores genealógicas derivadas de retrotransposons foram precisamente congruentes com árvores anteriormente estabelecidas com base em similaridades de sequências e características anatômicas. Se a transferência entre espécies explicasse a maioria dos retrotransposons compartilhados, não seria esperada tal congruência.
Em uma busca assistida por computador na literatura científica, pude encontrar apenas dois exemplos de pseudogenes para os quais a transmissão viral foi sequer considerada, mesmo que tentativamente, como um mecanismo de origem, em ambos os casos com evidências bastante fracas (Gruskin et al., PNAS 84:1605, 1987 e Robins et al., J Biol Chem 261:18, 1986). Os leitores que tiverem conhecimento de outros exemplos são convidados a enviá-los por e-mail para inclusão em futuras atualizações deste artigo. Por enquanto, as evidências argumentam contra a transferência interespecífica mediada por vírus como um mecanismo geral para explicar pseudogenes/retrotransposons compartilhados.
5.11 O criacionista L. J. Gibson também abordou pseudogenes em um artigo publicado (Origens 21:91, 1994). O artigo de Gibson resume-se a dois pontos, um semelhante ao discutido na seção 5.2 acima, mais um ponto adicional de natureza mais filosófica. Ele observa que o argumento dos pseudogenes compartilhados repousa sobre a premissa "de que Deus não criaria sequências não funcionais semelhantes em espécies separadas", o qual ele chama de "um argumento teológico [que] dificilmente pode ser abordado pela ciência" e que exigiria suporte bíblico para ser acreditado. Como a Bíblia não aborda — e, portanto, deixa em aberto — a possibilidade de que Deus possa criar sequências não funcionais no DNA, Gibson sente que não se pode descartar a noção de que Deus, de fato, criou tais sequências individualmente conforme criou cada espécie, incluindo aquelas sequências não funcionais que agora encontramos compartilhadas entre diferentes espécies.
Deve-se mencionar, entre parênteses, que o argumento de Gibson enfraquece a própria interpretação dos criacionistas sobre a semelhança entre espécies mencionada no início deste ensaio (seção 1.2). Como discutimos, os criacionistas têm alegado que as árvores de semelhança baseadas em informações de sequência não precisam ser aceitas como evidência para relações evolutivas, porque espécies independentemente criadas por um designer inteligente poderiam ser esperadas para mostrar padrões idênticos de aparente parentesco. A crítica de Gibson aplica-se igualmente bem a este argumento criacionista, já que a Bíblia não menciona os planos de Deus para a semelhança de sequências.
No entanto, como discutimos anteriormente, essa noção criacionista de sequências semelhantes projetadas para funções semelhantes faz, pelo menos, algum sentido intuitivo. Em contraste, Gibson propõe uma hipótese ad hoc claramente inaceitável quando sugere que um projetista poderia ter inserido retrotransposões não funcionais --imitando todas as características das que atualmente se retrotranspõem aleatoriamente no laboratório-- nas mesmas posições do DNA de espécies criadas independentemente; essa ideia merece tanto crédito quanto a alegação de que entradas falsas compartilhadas em um diretório são devidas a erros independentes em vez de plágio. A hipótese de Gibson não argumenta a favor de um criador que toma decisões de projeto compreensíveis, mas de um criador tão imprevisível que poderia ser o autor de qualquer descoberta científica tradicionalmente interpretada como não projetada --a menos que a Bíblia afirme especificamente o contrário. Assim, a lógica de Gibson apoiaria as seguintes afirmações, porque não são especificamente contraditas pela Bíblia: (1) Deus criou fósseis que pareciam restos de animais que nunca viveram e os embutiu em rochas. (2) Deus criou elementos radioativos em rochas que falsamente sugeririam idades maiores do que suas idades reais. (3) Deus criou o universo há 6000 anos com a luz das estrelas a caminho de nossos olhos, mas com as propriedades esperadas da luz que deixou estrelas bilhões de anos atrás. Em outras palavras, a lógica de Gibson nos convida a rejeitar qualquer argumento científico para a evolução se esse argumento não for especificamente verificado na Bíblia. A visão de Gibson pode ser internamente consistente, mas claramente exige que a verdade da Bíblia seja aceita por fé como base para julgar os méritos das conclusões científicas, e, portanto, afasta-se da verdadeira ciência baseada em testes de hipótese, lógica indutiva e conclusões baseadas em dados observados. Se um cientista vê uma retrotransposição inserindo-se no laboratório como resultado de vários parâmetros bioquímicos conhecidos, o barbeiro de Occam desencoraja-o de postular uma mão inteligente guiando sua criação. Se encontrarmos outras inserções em nosso DNA com características idênticas às que surgem sob observação, assumimos que as que estão em nosso DNA surgiram por um mecanismo semelhante. Sabemos que tais inserções que surgem sob observação laboratorial podem ser usadas para rastrear a linhagem de animais de laboratório, e que outras inserções naturais podem ser usadas para rastrear populações na natureza; não temos motivo para nos dissuadir de usar inserções semelhantes para rastrear as linhagens de diferentes espécies. Esse raciocínio indutivo é fundamental para a paleontologia, datação radioativa, astronomia, física, medicina e todos os outros campos da ciência. Se Gibson sente que os méritos de um argumento científico dependem de quão bem ele é apoiado pela Bíblia, ele pode simplesmente rejeitar a evolução de plano porque ela conflita com Gênesis, e evitar a incômoda tarefa de lidar com todos os detalhes das observações e deduções científicas individuais nas quais a evolução se baseia. Essa abordagem de "Bíblia em primeiro lugar" pode ser apropriada para a religião, mas é inaceitável como ciência.
6. Testando o modelo
Uma característica da ciência que a distingue da crença religiosa revelada (e dos evolucionistas dos criacionistas) é a convicção científica de que novos conhecimentos sobre o passado podem ser obtidos através da análise cuidadosamente projetada do mundo moderno. Os criacionistas frequentemente alegam que, como a origem das espécies ocorreu no distante passado, não há maneira cientificamente válida de estudar o processo hoje e, portanto, a evolução não é uma ciência real testável por experimento. No entanto, mesmo sem experimentos reais, uma hipótese científica pode ser testada se sugerir uma previsão não trivial que possa ser verificada ou falsificada pela coleta de mais dados.
De fato, a interpretação dos pseudogenes processados compartilhados descrita aqui representa uma hipótese que pode ser testada, pois apresenta uma implicação bastante surpreendente: a partir da comparação entre duas sequências de nucleotídeos de uma única espécie — ou seja, as sequências de um pseudogene processado e do gene funcional do qual ele derivou —, deve ser possível prever quais outras espécies compartilharão o mesmo pseudogene e quais não o compartilharão. Para compreender a lógica de tal previsão, considere o fato de que, se um pseudogene processado surgiu em uma espécie antiga, cópias desse pseudogene deveriam ser encontradas nos descendentes modernos dessa espécie. Assim, de acordo com o modelo evolutivo, se soubéssemos quando um pseudogene processado humano surgiu e pudéssemos, portanto, fixar sua origem em uma posição específica na árvore evolutiva aceita, preveríamos que o mesmo pseudogene processado deveria ser encontrado em espécies modernas que derivam desse ponto na árvore e não em qualquer outro ramo.
De fato, existe uma maneira de estimar quando um pseudogene processado específico foi formado. Acontece que as mutações "silenciosas" — ou seja, mutações que não têm efeito na sobrevivência do organismo (como todas as mutações em pseudogenes inúteis) — acumulam-se a uma taxa bastante uniforme. Esta taxa foi estimada examinando o número de diferenças de sequência "silenciosas" entre sequências sem função correspondentes em duas espécies e comparando este número com a data aproximada de divergência das mesmas duas espécies, conforme indicado pelo registro fóssil. Dada esta taxa de mutação e o número de diferenças de sequência entre um pseudogene processado específico e seu gene fonte funcional (da mesma espécie), pode-se estimar a data de origem do pseudogene; em seguida, com base nesta data, pode-se derivar previsões sobre quais outras espécies modernas devem carregar o mesmo pseudogene. Estas previsões podem ser testadas procurando pelo pseudogene em uma variedade de espécies.
Considere, por exemplo, o pseudogene humano epsilon processado discutido anteriormente (seção 4.3). O número de diferenças de nucleotídeos entre este pseudogene e o gene funcional sugere que este pseudogene surgiu há cerca de 40 milhões de anos. Portanto, a interpretação evolutiva de pseudogenes processados apresentada neste ensaio preveria que ratos e coelhos (que são considerados ter divergido da linhagem humana há 70 a 80 milhões de anos, antes da aparente origem do pseudogene) não deveriam carregar este pseudogene. Em contraste, os grandes símios e os macacos do Velho Mundo – cujas datas estimadas de divergência da linhagem humana (5-10 e 30 milhões de anos atrás, respectivamente) são ambas posteriores à aparente origem do pseudogene – seriam esperados para carregar o pseudogene. As evidências disponíveis confirmam todas essas previsões e também são consistentes com previsões semelhantes sobre a distribuição de espécies de outros pseudogenes processados (veja, por exemplo, Anagnou et al. PNAS 81:5170, 1984 em relação à dihidrofolato redutase, Craig et al. Gene 99:217, 1991 em relação à triosefosfato isomerase, e Friedberg e Rhoads Molec. Phylogenet & Evolution 16:127, 2000 em relação à enolase, calmodulina e argininosuccinato sintetase).
Por uma lógica semelhante, é possível estimar a idade da inserção de um retrovírus endógeno comparando as sequências dos LTR "esquerdo" e "direito" (ver seção 2.2.2.d acima). Como o LTR "esquerdo" é copiado da sequência do LTR "direito" no momento da inserção, os dois LTRs compartilham sequências idênticas no momento em que a cópia do retrovírus origina. Após a inserção, os dois LTRs acumulam mutações independentemente, e, portanto, o número de diferenças de sequência entre os dois LTRs pode ser usado para estimar a idade de uma inserção retroviral específica; essa idade pode ser usada para prever a distribuição de espécies de cópias compartilhadas da inserção retroviral específica. Quando as idades de vários retrovírus endógenos humanos foram estimadas recentemente usando essa abordagem, a distribuição de espécies prevista de cópias compartilhadas foi confirmada (Johnson & Coffin, PNAS 96:10254, 1999).
Embora as inserções individuais de SINE e LINE humanos não possam ser datadas facilmente apenas pela análise de sequências, pode ser possível estimar um período temporal aproximado quando certas subclasses se inseriram. Isso é possível porque classes específicas de retroposons semelhantes são consideradas ter povoado o genoma dos mamíferos em ondas, com certas famílias (e subfamílias, no caso das sequências Alu e LINE) sendo copiadas de um pequeno número de retroposons-fonte ativos em qualquer período particular de nossa história evolutiva. Este modelo foi deduzido do fato de que, para algumas famílias de retroposons humanos (por exemplo, LINE2), comparações entre membros específicos da família revelam sequências relativamente divergentes, como se cópias individuais tivessem acumulado muitas mutações diferentes ao longo de um longo tempo desde a inserção em nosso DNA (Nature 409:860, 2001, ver p. 881), enquanto outras, como as sequências Alu (particularmente as subfamílias Ya5 e Ya8) e a família Ta de sequências LINE1, mostram menos desvios de uma sequência consenso e, portanto, são consideradas ter se inserido mais recentemente. Essas interpretações baseadas na evolução das sequências de retroposons humanos preveem uma ampla compartilhamento de retroposons supostamente mais antigos entre espécies, mas um compartilhamento mais restrito dos supostamente mais jovens, e essas previsões são confirmadas por dados independentes de distribuição de espécies para esses retroposons (Gonzalez et al, Genomics 18:29, 1993; Shaikh e Deininger, J Mol Evol 42:15, 1996; Carroll et al, J Mol Bio 311:17, 2001; Sheen et al. Genome Res 10:1496, 2000; Boissinot et al., Mol Biol Evol 17:915, 2000).
Compartilhar mais retroposons certamente será descoberto, e apenas o tempo dirá com que consistência previsões evolutivas como estas são confirmadas. Mas, no momento, quase todos os dados disponíveis são consistentes com modelos evolutivos de descendência comum, e nenhuma justificativa criacionista alternativa para explicar esta consistência foi proposta. Instâncias repetidas deste tipo de previsão e confirmação podem fornecer evidências convincentes para a evolução, mesmo que alguns tipos de experimentos diretos, como estudos sobre dinossauros vivos, sejam impossíveis. (Se os leitores estiverem cientes de outros exemplos de pseudogenes processados ou outros retroposons cuja distribuição em diferentes espécies apoia ou contradiz a "árvore genealógica" aceita, apreciaria ouvir sobre esses casos por E-mail, e revisaria esta postagem conforme apropriado.)
7. Conclusão
As sequências sem função compartilhadas descritas aqui provam que humanos e primatas tiveram um ancestral comum? Na verdade, nenhum conhecimento científico se baseia em provas inabaláveis do tipo que sustentam teoremas matemáticos, portanto a queixa criacionista de que a evolução "nunca foi provada" simplesmente revela um grave mal-entendido sobre a natureza da ciência. Em vez disso, a ciência avança pela acumulação de pistas buscadas por detetives persistentes (cientistas) que tentam deduzir conclusões lógicas e imparciais a partir dessas pistas. Como um júri apresentado com essas pistas, podemos tentar chegar ao veredito mais provável, mesmo reconhecendo que nossos fatos são incompletos; não há "testemunhas" vivas dos eons da evolução, então devemos fazer as melhores deduções possíveis a partir das pistas disponíveis. No "caso das sequências sem função compartilhadas", um júri imparável certamente concluiria que copiar de um ancestral compartilhado era a explicação mais provável, consistente com a interpretação evolutiva. Essa conclusão seguiria a lógica da lei de direitos autorais real, na qual erros compartilhados são aceitos como evidência de cópia. A forte aceitação dessa conclusão entre os cientistas é indicada pelo fato de que nenhuma explicação alternativa foi proposta na literatura científica para explicar a ampla partilha de tantas sequências sem função entre espécies. Assim, se aceitarmos as evidências da ciência, parece que a descendência comum de espécies distintas de um ancestral compartilhado ("macroevolução" na terminologia criacionista) realmente ocorreu.
À medida que novos exemplos de pseudogenes e retrotransposons compartilhados são descobertos por geneticistas moleculares, essas informações se juntarão à imensa coleção de pistas de outras disciplinas que, coletivamente, já fornecem evidências esmagadoras para a evolução. Apesar dessa impressionante evidência, nenhum cientista acredita que todas as respostas sobre a evolução estejam prontas ou que nosso entendimento atual de pseudogenes e retrotransposons esteja imune a revisões à luz de futuros conhecimentos. De fato, cientistas em laboratórios em todo o mundo continuam a investigar os genes de várias espécies, comparando os dados de genética molecular com o registro fóssil e refinando nosso conhecimento da história da nossa espécie.
No estágio atual desta pesquisa interminável, as evidências sugerem o que para mim é uma noção impressionante: como uma Pedra de Roseta biológica ou um Manuscrito do Mar Morto, nosso próprio DNA — um valor equivalente à Enciclopédia Britânica de informações em cada célula do nosso corpo — contém um registro do passado que estamos apenas agora aprendendo a ler. Este registro, refletindo milhões de anos de história genética, inclui relíquias de antigos acidentes genéticos que ocorreram antes de nossos ancestrais semelhantes a macacos vagarem pelas planícies da África, relíquias que agora compartilhamos com outros descendentes desses mesmos ancestrais: gorilas modernos e chimpanzés.
| As Perguntas Frequentes | Arquivos Imperdíveis | Índice | Criacionismo | Evolução | Idade da Terra | Geologia do Dilúvio | Catastrofismo | Debates |